
作用域
pre:块语句
块语句(或其他语言的复合语句)用于组合零个或多个语句。该块由一对大括号界定,可以是labelled:
块语句会生成一个块级作用域,生成块级作用域包含两种方法:
使用任意声明符号(’’,
var,let,const)在函数中会生成一个块级作用域。使用
let,const在任何块语句中生成一个块级作用域。注意:
var在非函数的块语句中不会生成一个块级作用域。
介绍中都会使用var来进行举例,在变量声明中会对let和const进行说明。
介绍
变量的简单说作用域就是在哪里可以访问到该变量。在JavaScript中,变量的作用域分为
- 全局作用域。
- 局部作用域。
这个全局与局部是相对的。因为在浏览器环境下,window对象被称为全局对象(在ES6中,顶层对象被规范为globalThis对象,在node中会指向global对象。)。而相对的,函数中的变量被称为局部变量。特点如下:
- 局部变量只能在该作用域和其子作用域中访问到。
- 全部变量可以在任作用域中访问到。
例子
1 | var out = 'out-msg' |
作用域链
由于上面提到,全局与局部是相对的。由于window是浏览器环境中的最基础的变量,所以他被称为全局变量。而函数中(局部作用域)链中的还可以再定义函数,而内部函数仍然可以访问到外部函数中定义的变量。这样多个函数嵌套就会形成一个作用域链。
例子
1 | var a = 'window' |
所以,这样由window-fun1->fun2->fun3->func4形成了一个作用域链。
tip:
- 当要使用一个变量时,系统会按照作用域链的顺序向上依次查询。所以,变量名相同时,局部变量会优先被访问。
- 使用
var定义变量时,局部作用域只会在函数内部产生,当使用let,const时,只要是花括号内部,都会产生一个作用域。
变量申明
目前JavaScript中4中声明变量的方式:无声明标志,var,let,const
无声明标志
所谓不用声明标志,就是直接使用变量名进行声明,如
1 | a = 1 |
这样申明的变量有一些特点:
- 无论在哪里申明(即使是在函数块中),其都是一个全局变量,即会被挂载在全局对象
window上,即无声明标志无论如何都不会构成局部作用域。
var
var是ES6出现之前JavaScript中的声明标志之一(另外一个时function用来声明一个函数变量)。所以他也具有一些特征。
变量提升
变量的声明与赋值
在理解变量提升之前,我们要明白变量声明与变量赋值之间的关系。
变量声明是指确定这个作用域中该变量的存在。
1
var v
变量赋值就是为已经声明的变量进行赋值。
1
v = 'variable'
这两个操作可以一起进行。
1
var v = 'variable'
由于变量声明(以及其他声明)总是在任意代码执行之前处理的,所以在代码中的任意位置声明变量总是等效于在代码开头声明。这意味着变量可以在声明之前使用,这个行为叫做“hoisting”。“hoisting”就像是把所有的变量声明移动到函数或者全局代码的开头位置。
例子
1 | bla = 2 |
重要的是,提升将影响变量声明,而不会影响其值的初始化。当到达赋值语句时,该值将确实被分配:
1 | function do_something() { |
值得注意的是:
变量提升是在对应作用域下进行的,内层的作用域变量不会提升到外部中,所以会产生下面的问题:
1 | var ov = 'out' |
问结果是什么。
答:由于变量提升的按照作用域进行的,所以虽然这里外部声明了一个ov,但是在函数func内部也声明了一个ov变量,且在这个函数赋值之前就使用了,所以这里实际上等价于:
1 | var ov = 'out' |
而单独的变量声明不赋值,在JavaScript中其默认值为undefined,所以这里打印出来的是undefined
值得注意的是:
只要是在变量还没有赋值之前进行操作,其值都是undefined。如:
1 | var x = y, y = 'A' |
由于x = y时进行时,A还没有被赋值。但是由于变量提升,y是存在的,且其值为undefined,根据JavaScript的primitive算法,得x + y结果为undefinedA。
let
let声明符号是ES6引入的新的声明符号,为了解决var的一些问题。其有一下特点:
- 其在块语句中声明就会生成一个块级作用域(只要花括号存在)。
- 同一个变量名,只能被声明一次。
- 不会存在变量提升,取而代之的是暂时性死区。
下面依次解释:
其在块语句中声明就会生成一个块级作用域(只要花括号存在)。
以前JavaScript中只有全局作用域和函数作用域。而ES6引入的let与const相当于为JavaScript引入了块级作用域。
1 | function f1() { |
1 | {{{{ |
上面代码使用了一个五层的块级作用域,每一层都是一个单独的作用域。第四层作用域无法读取第五层作用域的内部变量。
同一个变量名,只能被声明一次。
使用var时,同一个变量名,可以被多次声明。如:
1 | var a = 123 |
但是使用let时,不允许重复声明同一个变量。
1 | let a = 123 |
不会存在变量提升,取而代之的是暂时性死区。
上面提到,使用var声明变量时,会存在变量提升的现象。即相当于所有的变量,无论何处声明,其都被在最顶部声明,且默认赋值为undefined,然后在运行到声明处,在会被赋值为对应的值。所以在声明之前使用该变量,其结果都是undefined。
而使用let声明时,在声明之前,是无法使用的。从程序开始之前,到声明之间,被称为暂时性死区。如:
1 | console.log(a) Uncaught ReferenceError: b is not defined |
立即执行函数(IIFE)
定义一个函数后将其立即执行的形式,形如:
1 | (function(){ |
其具有以下特点:
函数会立即执行
每执行一次,就会创建一个块级作用域,可以解决典型的异步问题:
1
2
3
4
5for(var i = 0; i < 5; i++){
setTimeout(function(){
console.log(i)
}, 500)
}众所周知,这里的结果是:
555~,其原因就是:setTimeout是一个异步函数,当其回调函数执行的时候,for循环,已经完成了。所以后面打印出来的都是4。- 用
var时,不存在块级作用域,所以一个for循环中,使用的都是同一个i,导致前面的i会被后面的i所覆盖。
所以前面提到
IIFE每执行一次都会创建一个快进作用域,所以可以这么解决。1
2
3
4
5for(var i = 0; i < 5; i++){
(function(i){
console.log(i)
})(i)
}这样其结果就是:1234
但是当ES6的let出现之后,我们不再需要立即执行函数了来创建块级作用域了。直接使用let进行变量声明即可:
1 | for(let i = 0; i < 5; i++){ |
其结果也是:1234
块级作用域的出现,实际上使得获得广泛应用的匿名立即执行函数表达式(匿名 IIFE)不再必要了。
1 | // IIFE 写法 |
const
const也是ES6引入的声明符号。其基本与let一致:
每使用一次都会创建一个块级作用域。
同一个变量名,只能被声明一次。
并且,其还有一下特征:
const声明一个只读的常量。一旦声明,常量的值就不能改变。const声明的变量不得改变值,这意味着,const一旦声明变量,就必须立即初始化,不能留到以后赋值。1
2const foo;
// SyntaxError: Missing initializer in const declaration
值得注意的是:变量不可以被更改,但是其属性是可以被更改的。如:
1 | const obj = { |
垃圾回收机制
基于最开始JavaScript设计的初衷,JavaScript的内存管理都是自动执行的,而且是不可见的。程序员基本上不需要自动管理内存。
V8内存模型
要想更好的理解JavaScript的内存回收机制,要先简单理解一下JavaScript的内存模型(这里以V8为例)
首先JavaScript的变量分为两大类:
- 基本变量
NumberBooleanStringSymbolBigIntnullundefined
- 引用变量:
Object,Array,Date,RegExp
然后看一下V8的内存模型:

栈区
栈区用于存储变量的名称以及内存中的地址。该地址又指向堆区、常量区或函数定义区。
例如:
在我们定义一个变量时:
1 | var a = 'string' |
a为基本类型,所以他的值存储在池(常量区),所以:
- 在栈区建立一个单元:|变量名|内存地址|(如
|a|0x1245a|) - 在池(常量区)的
0x1245a存储’string’
b为引用类型,其值存储在堆区,所以:
- 在栈区建立一个单元:|变量名|内存地址|(如
|b|0x1245b|) - 在堆的
0x1245b的位置存储{}
值得注意的是:
变量未被初始化或者被赋值为undefined时,栈区的地址部分被置空。表示没有任何意义。
堆区
用于存放引用类型的值,如上面的b,其具体的值就存储在堆区。
值得注意的是:
在堆区,预存着一个特殊对象null,其地址固定,所有的值为null的变量都指向这一块内存。
所以,需要手动释放一个变量时,只需要将该变量赋值为null,则此时其指向null,原来的内存在无引用时会被GC(garbage recycle)机制回收。
常量区
与堆区相对,其存储常量的值。如上面的a变量。
常量区具有以下特征:
- 所有的值一旦写入无法改变。
- 所有相同的常量值在常量区都是惟一的。
注意:常量区的值与常量是不同的。常量区的值不可改变是指对应地址的内存内容是无法改变的。而当我们在改变常量时,实际上大概是这么个流程:
- 先检索常量区是否存在新的变量值。
- 如果存在,则直接将栈区的地址改为该常量的地址;若不存在,则在常量区新开辟一个地区,将新的变量存储到该地址,再将该常量的地址改为新的内存地址。
函数定义区
函数定义区用于存放被定义的函数代码段。
值得注意的是:函数的声明有两种:
函数声明,形如
1
2
3function func(){
//...
}这种定义的方式不会再栈区生成相应的函数名,因为此时其不是一个变量。引擎会直接在函数定义区定义这个函数,我们在调用这个函数的时候,引擎会去函数定义区搜索这个函数名进行调用。
函数引用,形如:
1
2
3var func = function(){
//...
}这种方式会在栈区生成一个变量来保存这个函数的地址。函数代码段仍然保存在函数定义区。
两种定义方式在调用的时候会表现出一些不同。
- 对于第一种方式,V8引擎会在预扫描阶段进行函数提升,也就是说,你可以在函数定义之前调用该函数;
- 对于第二种方式,尽管引擎也会进行变量提升(因为其本身就是一个变量),但是并不会在提升的时候对变量赋值,因此不可以在定义之前调用该函数。
1 | //可以正常调用,因为引擎会提前扫描代码,将该函数存储到函数定义区 |
- 另外,如果函数名发生了重名,浏览器会以通过栈区变量引用的函数优先。如:
1 | var f = function(){} |
之所以出现这种情况,是因为JavaScript引擎总是优先搜索栈区,所以上面的函数会优先被调用。但是如果调用发生在函数定义之前,那么就会调用通过函数声明定义的函数,代码如下:
1 | //会调用下面的以函数声明定义的函数 |
究其原因,还是在调用函数时变量f的值为undefined,因此引擎才会去函数定义区搜索函数f。总的来说,引擎在调用函数时会以栈区的变量优先,如果搜索不到或为undefined,则会去函数定义区搜索。
但是两者实际上并不冲突,我们同样可以用一个变量来指向一个声明式函数,如:
1 | function f(){} |
现在变量g也拿到了函数f的内存地址,使用g同样可以访问该函数。
函数缓冲区
函数缓冲区用于存放函数运行时动态申请的空间。函数运行时引擎会为其分配一片空间。当函数运行结束后,会回收其空间。只有当闭包产生的时候才会保留函数缓冲区中的数据。
垃圾回收机制
JavaScript 中内存管理的主要概念是可达性(Reachability)。简单地说,“可达性” 值就是那些以某种方式可访问或可用的值,它们被保证存储在内存中。
从上面的内存分配可以看出,每一个变量都会在栈区存储其名字和地址,地址又指向堆区或池。所以JavaScript的GC机制就是当不存在一个变量指向一个内存地址,则引擎认定该内存可以被回收。
这其中有一部分变量是一定可达的,被称为根(root),如:
- 全局对象
- 正被调用的函数的局部变量和参数
- 相关嵌套函数里的变量和参数
- 其他(引擎内部调用的一些变量)
这些根上面挂载的变量则也一定可达。
具体比如:
1 | let num = 123 |
此时内存分配结构为:
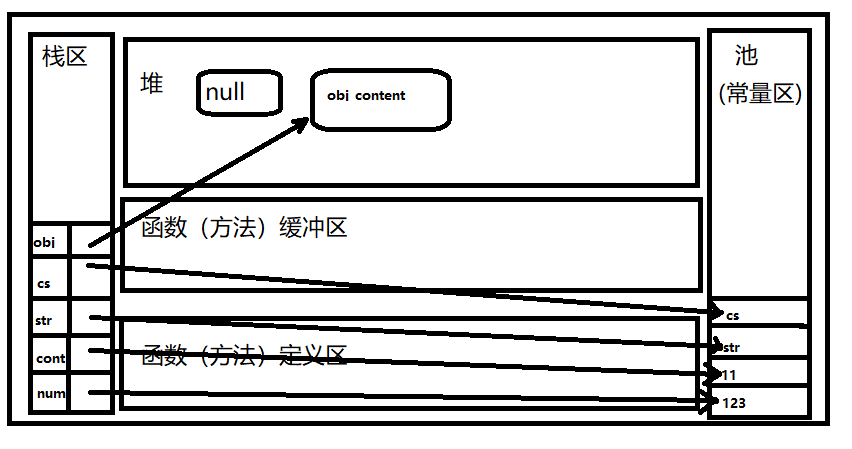
即池和堆中的每个被分配的内存块都可以通过栈区的变量访问到。所以他们都是可达的,故不会被GC回收。
但是当我们将某一个变量赋为null时候,原来堆池中的值就变成不可达,GC就会进行回收。如:
1 | let num = 123 |
这个时候把所有的基础变量都置为null,则本来按照回收机制,其所有的基础变量都会被GC回收,但是由于obj中引用了cont,cs,所以虽然这两个变量被置为null了,但是内存中实际的值并没有被回收。此时其内存状况如下
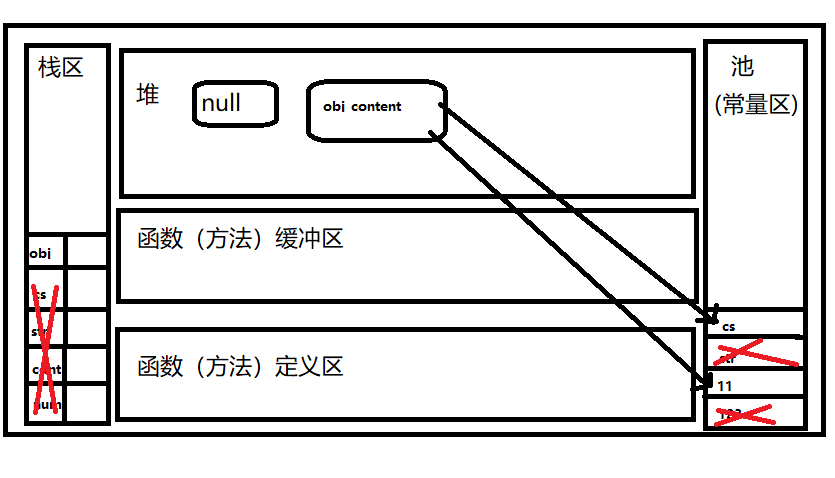
可以看到由于可以从obj访问到cs,11,所以他们不会被回收。
回收算法(精简版)
基本的垃圾回收算法称为“标记-清除”,定期执行以下“垃圾回收”步骤:
垃圾回收器获取根并“标记”(记住)它们。
然后它访问并“标记”所有来自它们的引用。
然后它访问标记的对象并标记它们的引用。所有被访问的对象都被记住,以便以后不再访问同一个对象两次。
以此类推,直到有未访问的引用(可以从根访问)为止。
除标记的对象外,所有对象都被删除。
下面是一个简单的过程(via前端面试:谈谈 JS 垃圾回收机制](https://segmentfault.com/a/1190000018605776)):
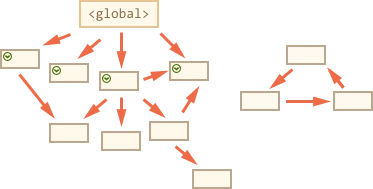
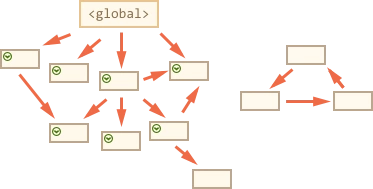
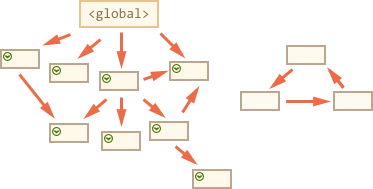
可以看出,这实际上是一个广度遍历的过程,对整个栈区的变量构成的图进行广度遍历,并对遍历到的内存坐下标记。当遍历完成时,内存中未被遍历到的内存则证明时不可达的,则GC则可以将其回收。
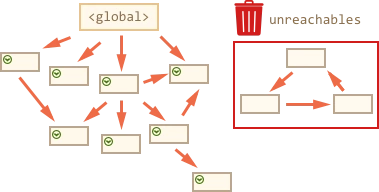
剩下的内存是不可达的,则会被回收。
上面就是垃圾收集的工作原理。JavaScript引擎应用了许多优化,使其运行得更快,并且不影响执行。
一些优化:
- 分代回收——对象分为两组:“新对象”和“旧对象”。许多对象出现,完成它们的工作并迅速结 ,它们很快就会被清理干净。那些活得足够久的对象,会变“老”,并且很少接受检查。
- 增量回收——如果有很多对象,并且我们试图一次遍历并标记整个对象集,那么可能会花费一些时间,并在执行中会有一定的延迟。因此,引擎试图将垃圾回收分解为多个部分。然后,各个部分分别执行。这需要额外的标记来跟踪变化,这样有很多微小的延迟,而不是很大的延迟。
- 空闲时间收集——垃圾回收器只在 CPU 空闲时运行,以减少对执行的可能影响。
闭包
上面谈了这么多,都是为了更好的理解闭包。既然理解了内存模型和垃圾回收机制,再理解闭包就是如鱼得水了。
首先我们知道函数内的变量的生命周期只是该函数的运行过程。函数运行一旦结束,函数内的变量就会从函数缓冲区中删除掉。但是有的时候我们需要将函数中的变量永久(或长时间)保存下来,这个时候只需要在函数内部再新建一个函数,并且再内层函数中使用外层函数的变量。再将内层函数作为结果返回出来。由于此时外层函数中的变量由于被内层函数中使用,所以他们是可达的,则GC不会将其回收。如:
1 | function out(){ |
这里就是一个典型的闭包。我们将使用外层函数的内部函数作为结果返回。我们调用该返回函数就可以操作到外层函数的变量。
闭包的应用
用闭包模拟私有方法
编程语言中,比如 Java,是支持将方法声明为私有的,即它们只能被同一个类中的其它方法所调用。
而 JavaScript 没有这种原生支持,但我们可以使用闭包来模拟私有方法。私有方法不仅仅有利于限制对代码的访问:还提供了管理全局命名空间的强大能力,避免非核心的方法弄乱了代码的公共接口部分。
下面的示例展现了如何使用闭包来定义公共函数,并令其可以访问私有函数和变量。这个方式也称为 模块模式(module pattern):
1 | var Counter = (function() { |
在之前的示例中,每个闭包都有它自己的词法环境;而这次我们只创建了一个词法环境,为三个函数所共享:Counter.increment,``Counter.decrement 和 Counter.value。
该共享环境创建于一个立即执行的匿名函数体内。这个环境中包含两个私有项:名为 privateCounter 的变量和名为 changeBy 的函数。这两项都无法在这个匿名函数外部直接访问。必须通过匿名函数返回的三个公共函数访问。
这三个公共函数是共享同一个环境的闭包。多亏 JavaScript 的词法作用域,它们都可以访问 privateCounter 变量和 changeBy 函数。
你应该注意到我们定义了一个匿名函数,用于创建一个计数器。我们立即执行了这个匿名函数,并将他的值赋给了变量Counter。我们可以把这个函数储存在另外一个变量makeCounter中,并用他来创建多个计数器。
使用闭包形成一个块级作用域,完成异步回调函数(这里使用let解决更好)
就像上面的IIFE中,我们使用了闭包来形成一个块级作用域,来完成异步回调函数,不至于造成异步函数执行时循环以完毕。
1 | for (var i = 0; i < helpText.length; i++) { |
这里就是利用闭包形成了一个块级作用域。使每一次循环都有一个作用域,使在异步回调执行的时候,其值是正确的。