
在浏览器地址栏输入URL后回车,背后所经历的步骤
浏览器层面
0、URL解析
现在几乎所有浏览器都实现了地址栏快捷搜索的功能,所以这里需要判断用户输入的到底是关键词还是地址,然后进行不同的操作。
关键字
使用浏览器内置的搜索引擎地址与关键词来拼接得到最终的URL。
URL
对URL进行补全,编码转换等工作。
例如:用户在输入URL时,一般都不会携带协议与端口。当用户输入baidu.com的时候,浏览器会将其补全为:
https://baidu.com:80。
chrome默认是补全https协议
其他操作
浏览器还会进行其他操作,比如
历史记录缓存检查
这一步即可以让我们直接访问之前访问过的URL。
访问限制
有些浏览器会对部分网站进行拦截。
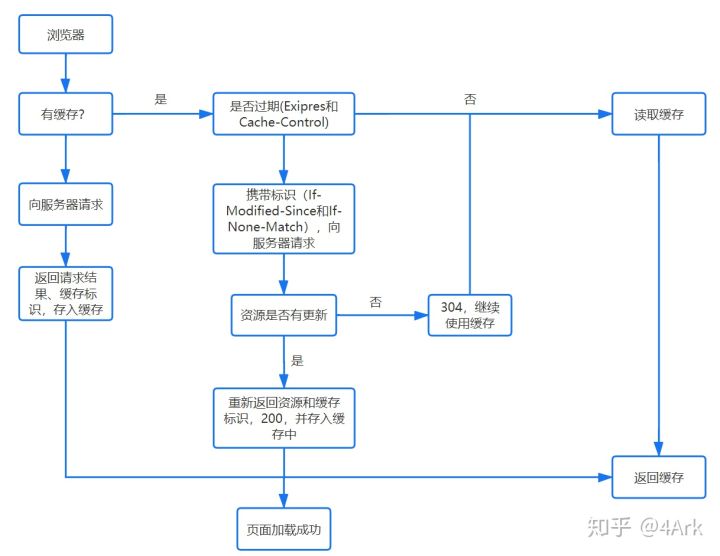
1、缓存检查
根据浏览器缓存原则,其会优先检查本地是否已经有缓存文件,然后再向服务器发送请求,具体流程如下:
2.1、 浏览器检查DNS缓存(DNS查询1)
浏览器检查自己是否有该域名的DNS的缓存。
操作系统层面
2.2、 操作系统检查DNS缓存(DNS查询2)
如果浏览器查询DNS失败,则调用系统的API进行DNS查询,系统则会先检查自己的本地缓存文件。
2.3、 路由器检查DNS缓存(DNS查询3)
系统在本地文件中没有发现改DNS条目的时候,请求会依次向上请求,其中路由器也会保有自己的DNS表,也会进行查询。
2.4、ISP(Internet Service Provider) DNS缓存
即互联网服务提供商(移动、联通、典型等)的DNS缓存服务器。
2.5、根域名服务器查询DNS缓存
根域名服务是最高层次的域名服务器。所有的根域名服务器都知道所有的顶级域名服务器的域名和IP地址。
如果上面几步都没有查询到对应的DNS缓存,则请求会被发送到根域名服务器查询。
2.6、顶级域名服务器查询(如:org域名服务器、com域名服务器、deu域名服务器)
在多数情况下,根域名服务器并不会直接返回IP地址,而是告诉请求应该去请求哪一个顶级服务器(即告诉该顶级服务器的IP地址,系统再请求顶级服务器拿到目标IP地址)
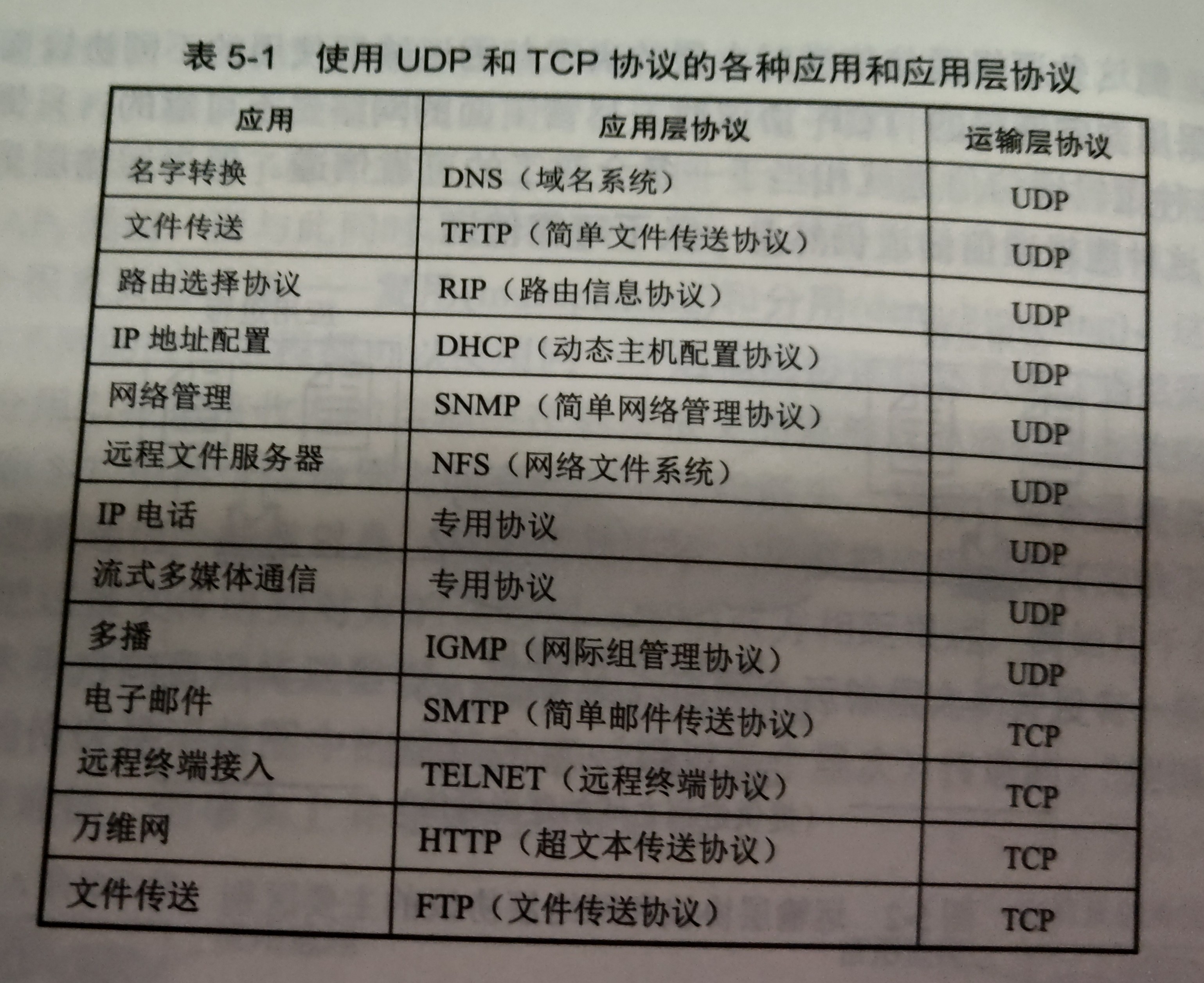
注意:应用层的DNS(域名系统)在传输层采用的是UDP协议。下面是运输层与应用的对应:
建立TCP链接
由于HTTP协议是建立在TCP协议之上,所以客户端与服务器之间需要先建立TCP连接,然后再在TCP连接之上发送HTTP请求。
注意:在五层协议中:
- 应用层
- 传输层
- 网络层
- 数据链路层
- 物理层
中,上面4层都会有一个头部head来对正文进行封装,物理层传输的数据单位是bit,所以流程大概如下:
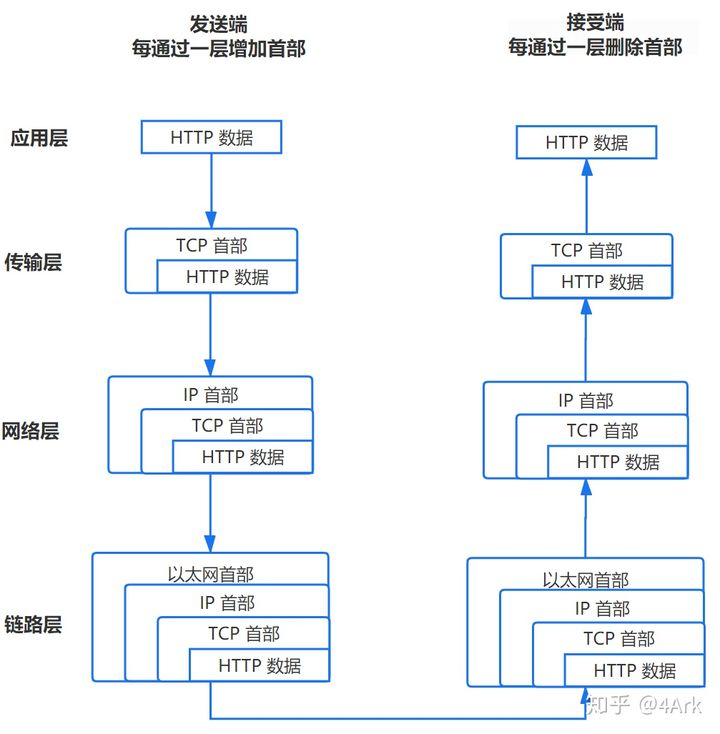
在服务器接受到数据包后,会对报文进行一层一层的去头部,并在每层进行处理,主要是在传输层,TCP协议会进行连接确定,即三次握手过程。
第一次
第一次握手:建立连接时,客户端发送syn包(初始序号seq=j)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。注意:这个请求不能带数据,但是会消耗一个序号。
第二次
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(seq=k),即SYN+ACK包(即把报文中的SYN和ACK都设为1),此时服务器进入SYN_RECV状态。
第三次
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
HTTP请求
客户端请求
由于HTTP是无状态的,所以HTTP只能一次一次的进行。在客户端与服务器建立TCP连接后,客户端开始发送HTTP请求,此处URL的请求是GET方式的。
服务器返回
接受请求
在HTTP请求到达服务器之后,一般会有一些容器来监听HTTP请求,具体的容器有:
- Apache
- Nginx
- IIS
这些容器会开启一个子进程来处理这个请求。
处理请求
接受HTTP报文后,会对其进行解析,获得其中的一些参数(请求方法、域名、路径、来源等),然后对其中的一些参数进行验证:
验证是否接受此方法
验证请求的地址是否正确
等
重定向
如果服务器对该请求地址配置了HTTP重定向,则会返回301永久重定向响应,浏览器会根据响应,重新发送HTTP请求到重定向地址。
浏览器层面(接受HTTP请求)
浏览器在接受到服务器的响应消息后,会对资源进行分析。
首先是分析Response header,根据状态码做具体的动作。
如果进行了压缩(比如gzip),还需要进行解压。
然后对相应资源做缓存。
然后根据响应资源里的MIME类型去解析响应内容(比如HTML,JSON等)
渲染页面(如果响应是HTML文件)
浏览器渲染过程很复杂,其基本流程为:
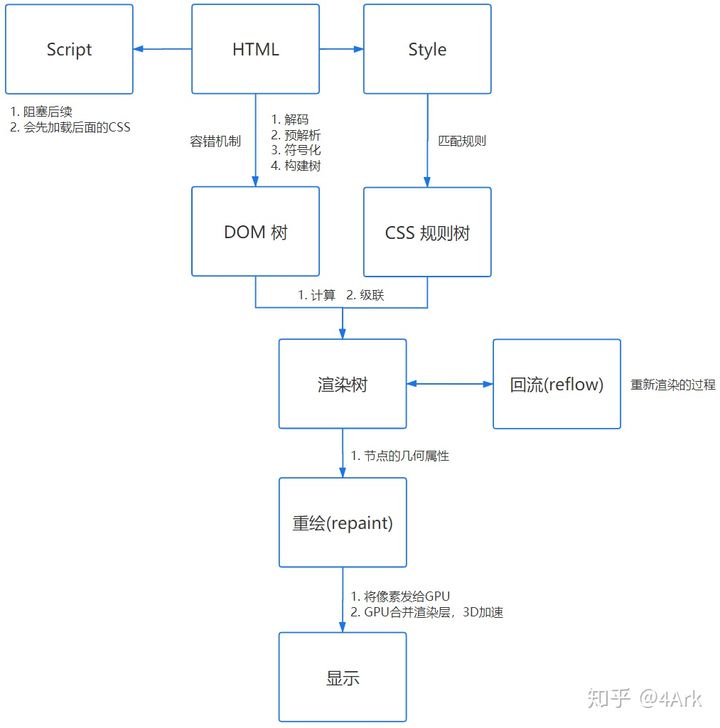
HTML解析(构建DOM树)
1. 解码(encoding)
传输回来的其实一些二进制数据,浏览器需要根据文件指定编码(例如UTF-8)转换成字符串,也就是HTML代码。
2.预解析(pre-parsing)
预解析做的事情是提前加载资源,减少处理事件,系统会识别一些请求资源的属性,比如img标签,video的src属性,并将其加入到请求队列中。
3. 符号化(Tokenization)
符号化就是词法分析的过程,将HTML代码解析成为符号,HTML符号包括,开始标签、结束标签、属性名和属性值。
4. 构建树
注意:符号化和构建树是并行操作的,也就是说只要解析到一个开始标签,就会创建一个 DOM 节点。
在上一步符号化中,解析器获得这些标记,然后以合适的方法创建DOM对象并把这些符号插入到DOM对象中。
CSS解析(构建CSSOM树)
当CSS被下载后,CSS解析器就会处理任何CSS,根据语法规范解析出所有的CSS并进行标记化,然后我们得到一个规则表。
CSS匹配规则
在匹配一个节点对应的CSS规则时,是按照从右到左的顺序,例如div p { font-size :14px },会先寻找所有的p标签然后判断它的父元素是否为div。
所以我们在写选择器的时候,尽量用id和class,不要用太多层级的选择器。
渲染树
这个过程是一个DOM树与CSS规则树合并的过程。
注意:渲染树会忽略那些不需要渲染的节点,比如设置了
display:none的节点。
计算
通过计算让任何尺寸值都减少到三个可能之一:auto、百分比、px,比如把rem转化为px。
级联
浏览器需要一种方法来确定哪些样式才真正需要应用到对应元素,所以它使用一个叫做specificity的公式,这个公式会通过:
!important- 内联样式
- id、class、标签名
的顺序来计算准确的样式。
渲染阻塞
在JavaScript宏任务,微任务与Event-loop中,简单介绍了浏览器进程,其中一点是JavaScript线程与GUI渲染线程无法同时进行,遇到JavaScript标签,就会暂停DOM树的解析。
所以如果要对DOM树进行操作或者不阻塞页面,应当将script标签放在body标签的底部,或者使用defer与async,下面是defer与async的区别:

布局与绘制
确定渲染树中的所有节点的几何属性,位置,大小等。最后输入一个盒模型,然后遍历渲染树,将其渲染在屏幕中。
合并渲染层
将以上绘制的所有图片合并,最终输出一张图片。
回流与重绘
回流(reflow)
当浏览器发现某个部分发生变化并且影响了布局时,需要倒回去重新渲染,会从html标签开始递归往下,重新计算位置和大小。
因为回流可能导致整个dom树的重新构造,所以会影响性能。
重绘(repaint)
当浏览器发现某个部分发生变化但是没有影响布局的时候,比如:改变某个元素的背景色,文字颜色等,就会发生重回。
每次重绘后,浏览器还需合并渲染层并输出到屏幕上。
回流的成本要比重绘高很多,所以我们应该尽量避免产生回流。
比如:
display:none会触发回流,而visibility:hidden只会触发重绘。
因为:
display:none会脱离文档流,不占据页面空间;
visibility:hidden,只是隐藏内容,并没有脱离文档流,会占据页面的空间。
JavaScript编译执行
这里涉及到编译原理的过程,大概是:
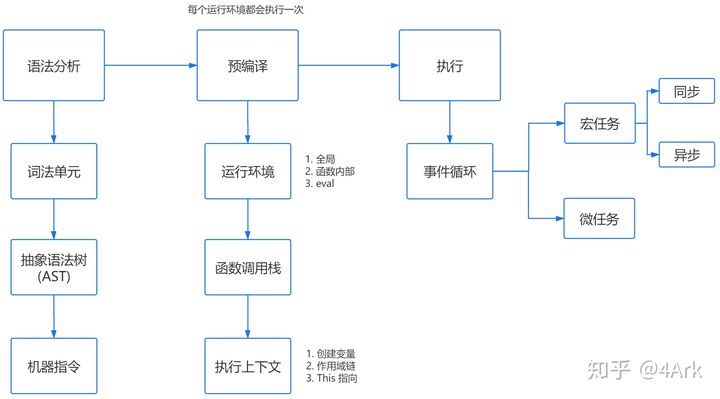
1. 词法分析
JavaScript脚本加载完成后,会首先进入词法分析阶段,首先会分析代码块的语法是否正确,不正确则抛出“语法错误”,停止执行。具体有:
- 分词,例如将
var a = 2,分成var、a、=,2这样的词法单元。 - 解析:将词法单元转换为抽象语法树
AST。 - 代码生成,将抽象语法树转换成机器指令。
2. 预编译
JavaScript中有三种运行环境:
- 全局环境
- 函数环境
- eval
(ES6的let,const会生成块级作用域)
每进入一个不同的运行环境都会创建一个对应的执行上下文,根据不同的上下文环境,形成一个函数调用栈,栈底永远是全局执行上下文,栈顶则永远是当前执行上下文。
参考
- 在浏览器输入 URL 回车之后发生了什么(超详细版)
- 计算机网络-谢希仁