
CommonJS规范
commonJS制定了一套模块的规范,来解决当时JavaScript中没有完善的模块机制,但是现在ES Module已经比较成熟了,在前端工程化开发中大部分都是用的ES Module来进行模块的导入导出。
由于内容比较多,之前在JavaScript中的模块导入导出中已经介绍过基本用法。详细的内容可以看这里。
Node的模块实现
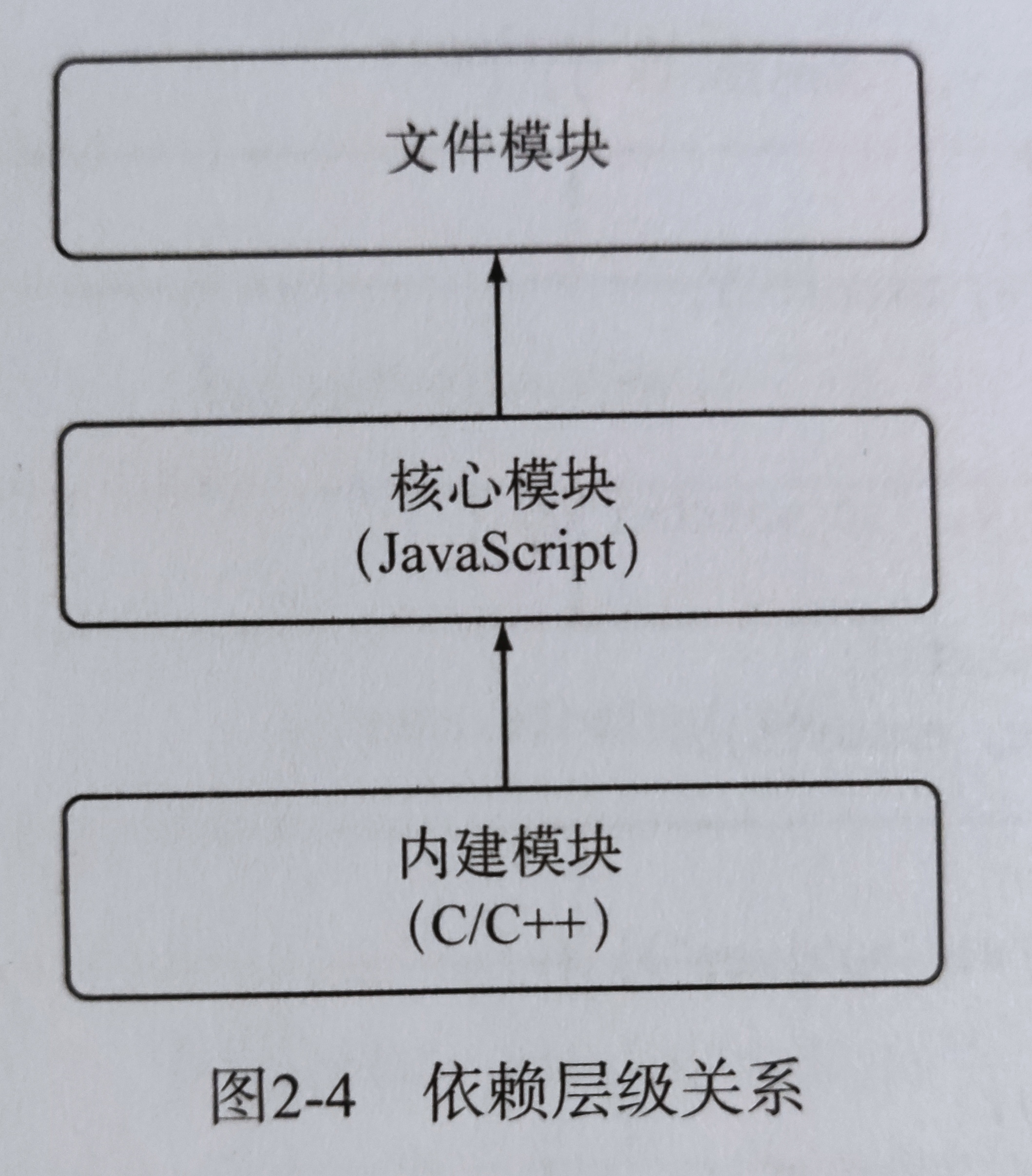
Node中,模块总的分为两类:
- 核心模块:由Node提供的模块
- 文件模块:由用户编写的模块
这两类模块都会经过以下三个步骤:
- 路径分析
- 文件定位
- 编译执行
注意:
- 核心模块部分在Node源代码中就被编译为了二进制文件。Node在启动时即被载入到内存中,所以这部分核心模块在引入的时候,文件定位和编译执行这两个步骤可以省略掉,所以其加载速度要快于文件模块。文件模块则是在运行时动态加载的,需要完整的路径分析,文件定位和编译执行过程,所以起运行速度要慢于核心模块。
- Node是默认缓存加载为第一优先级,无论是核心模块还是文件模块。require()方法对相同模块的二次加载一律采用缓存优先的方式。
路径分析
由于require()函数接受多种标识符,所以不同标识符也有不同的分析方法。大致分为以下几类:
- 核心模块,如:http, fs, path等
- 以
.或..开始的相对路径文件模块 - 以
/开始的绝对路径文件模块 - 非核心路径的文件模块,如自定义的connect模块
核心模块
核心模块的优先级仅次于缓存加载,其在Node中的源代码编译过程中已经编译为了二进制代码,其加载速度最快。
由于其优先级高于自定义模块,所以我们定义一个标识符与核心模块相同的自定义模块是无法被成功加载的。
路径形式的文件模块
以.或..开始的标识符,都会被当作文件模块来处理。并且在初次加载时会将其转换为真实路径,并以真实路径作为索引,将编译执行后的结果存放到缓存中,以使二次加载时更快。
自定义模块
自定义模块指的是非核心模块,也不是路径形式的标识符。它是一种页数的文件模块,可能是一个文件或者包的形式。这类模块的查找是最费时的,也是所有方式中最慢的一种。这与CommonJS中规定的node_modules的模块文件夹有关,但是在Node中的自定义模块的查找是一个与JavaScript中原型链查找相似,Node首先查找当前目录下的node_modules文件夹下是否存在该模块(注意这里的文件名在下面讲),然后查看父级目录下的node_modules是否存在该模块,再查看父级目录的父级目录是否存在node_modules,形成了一个链。只要在更近一层中发现该模块,即不再向外查找。
由于这种递归式的查找,所以其速度是最慢的。
模块路径:
模块路径是Node在定位文件模块的具体文件时制定的查找策略,具体表现为一个路径组成的数组。其本质就是前面提到的,当前目录下的mode_modules文件夹,父级目录下的mode_modules文件夹,父级目录的父级目录下的node_modules。
所以当我们新建一个js文件(该文件可以放在任意目录下),然后输入console.log(module.paths)。
执行该文件后就会得到一个类似下面数组的输出:
1 | [ |
文件定位
文件扩展名分析
require()函数接受不包含扩展名的文件标识符。这种情况下,Node会按.js,.json,node的次序补足扩展名,依次尝试。
在尝试的过程中,需要调用fs模块同步阻塞式的判断文件是否存在,由于Node是单线程的,所以这里可能会引起一点性能问题。所以,在使用node,json文件时,加上扩展名,会稍微提高一点速度。另外就是可以使用缓存机制,也可以大幅度的环节Node单线程阻塞调用的缺陷。
目录分析和包
在分析标识符的过程中,require()通过分析文件扩展名之后,可能没有发现对应文件,但是确得到了一个目录,这在引入自定义模块和组个模块路径进行查找时经常出现。此时,Node会将该目录作为一个包来处理。
此时,Node会在当前目录下查找package.json文件(CommonJS包规范定义的包描述文件),通过JSON.parse()解析出包描述对象。从中取得mian属性指定的文件进行定位。如果文件名缺少扩展名,将会重复上面的扩展名分析过程。
如果mian属性指定的文件名错误,或者和没有package.json文件,Node会将index当作默认文件名,然后依次尝试查找index.js,index.json,index.node。
如果上面的过程都没有定位到任何文件,则定义模块进入下一个模块路径(上一级路径)进行查找。
如果所有路径数组都被遍历完毕,依然没有查找到目标文件,则会抛出查找失败的异常。
模块编译
在Node中,每个文件模块都是一个对象,它的定义如下:
1 | function Module(id, parent){ |
编译和执行时引入文件模块的最后一个阶段。定位到具体文件后,Node会新建一个模块对象,然后根据路径载入并编译。具体不同的文件会有不同的处理方法:
- js文件:通过fs模块同步读取文件后编译执行。
- node文件:用C/C++编写的扩展文件,通过dlopen()方法加载最后编译生效的文件。
- json文件:通过fs模块同步读取文件后,用
JSON.parse()解析返回结果。 - 其余扩展名文件:它们会被当作js文件载入。
JavaScript模块的编译
在编译的过程中,Node对获取的JavaScript文件内容进行了头尾包装。在头部添加了(function(exports, require, __filename, __dirname){\n,在尾部添加了\n}),则一个正常的JavaScript文件会被包装成如下的样子:
1 | (function(exports, require, module, __filename, __dirname){ |
即形成了一个闭包,这样每个模块文件之间都进行了作用域隔离。包装过后的代码会通过vm原生的runInThisContext()方法执行(类似于eval,只是具有明确的上下文,不污染全局),返回一个function对象。在这一个过程后,模块就会具有exports属性,require方法,module(模块对象自身),以及在文件定位中得到的完整文件路径和文件目录作为参数传递给这个funciton执行。
注意:模块中的exports是module.export的一个形参传递,所以我们必须向module.export添加对象,否则无法添加导出属性。
C/C++模块的编译
Node调用process.dlopen()方法进行加载和执行。在Node的架构下,dlopen()方法在Windows和*nix平台下分别有不同的实现,通过libnv兼容层进行了封装。
实际上,.node的模块文件并不需要编译,因为它是编写C/C++模块之后编译产生的,所以这里只有加载和执行过程。在执行过程中,模块的exports对象与.node魔窟啊产生联系,然后返回给调用者。
C/C++模块给Node使用者带来的优势主要是执行效率方面的,劣势则是C/C++模块的编写门槛比JavaScript高。
JSON文件的编译
.json文件的编译是3种编译方式中最简单的。Node利用fs模块同步读取JSON文件文件的内容之后,调用JSON.parse()方法得到对象,然后将它赋值给模块对象的exports,以供外部调用。
JSON文件在用做项目的配置文件时比较有用。如果你定义了一个JSON文件作为配置,那就不必调用fs模块去异步读取和解析,直接调用require()即可引入。
核心模块
Node的核心模块在编译成为可执行文件的过程中被编译进了二进制文件,核心模块也分为C/C++编写的和JavaScript编写的两部分,期中C/C++文件存放在Node项目中的src目录下,JavaScript文件存放在lib目录下。
JavaScript核心模块的编译过程
在编译所有C/C++文件之前,编译程序需要将所有的JavaScript模块文件编译为C/C++代码,但此时并不会将其编译为可以执行的C/C++代码,而是将其以字符串的形式存储在数组中。具体过程如下:
转存为C/C++代码
Node采用了V8自带的js2c.py工具,将所有内置的JavaScript代码(src/node.js和lib/*.js)转换为C++里的数组,生成node_natives.h头文件中。
在这个过程中,JavaScript代码以字符串的形式存储在node命名空间中,是不可直接执行的。在启动Node进程时,JavaScript代码直接加载进内存中。在加载的过程中,JavaScript核心模块经历标识符分析后直接定位到内存中,比普通的文件模块从磁盘中一处一处查找要快很多。
编译JavaScript核心模块
lib目录下的所有文件也没有定义require,module,exports这些变量。所以也需要经历文件模块的编译过程。但与文件模块不同的是:获取源代码的位置,核心模块在启动时就被载入内存,所以调用时是直接从内存中取;而文件模块还需要从磁盘中读取。这个速度差别很大。
在代码实现中是通过process.binding('natives')取出,编译成功的模块缓存到NativeModule._cache对象中,文件模块则缓存到Module._cache上。
1 | function NativeModule(id){ |
C/C++模块的编译过程
在核心模块中,大致分为两类:
全部由C/C++编写,我们称为内建模块。
由C/C++完成核心部分,其他部分则由JavaScript实现包装或向外导出。
第二种情况下 一 般是以C/C++完成核心功能,由JavaScript实现包装或向外导出,这样可以平衡脚本语言与静态语言的开发速度与运行效率。
内建模块的组织形式
在Node中,内建模块的内部结构定义如下,其在node.h中:
1 | struct node_module { |
每个内建模块在定义之后,都通过NODE_MODULE宏定义到node命名空间中,模块的具体初始化方法挂在为结构的register_func成员:
1 |
|
node_extensions.h文件将这些散列的内建模块统一放进了一个叫node_module_list的数组中,这些模块有:
- node_buffer
- node_crypto
- node_evals
- node_fs
- node_http_parser
- node_os
- node_zlib
- node_timer_wrap
- node_udp_wrap
- node_pipe_wrap
- node_cares_wrap
- node_tty_wrap
- node_process_wrap
- node_fs_event_wrap
- node_signal_watcher
这些内建模块通过Node提供的get_buildin_module()方法从node_module_list数组中取出这些模块。
内建模块的优势:
- 由C/C++编写,所以性能上由于脚本语言。
- 直接被加载收到内存中,速度快于从磁盘中查找。
内建模块的导入导出
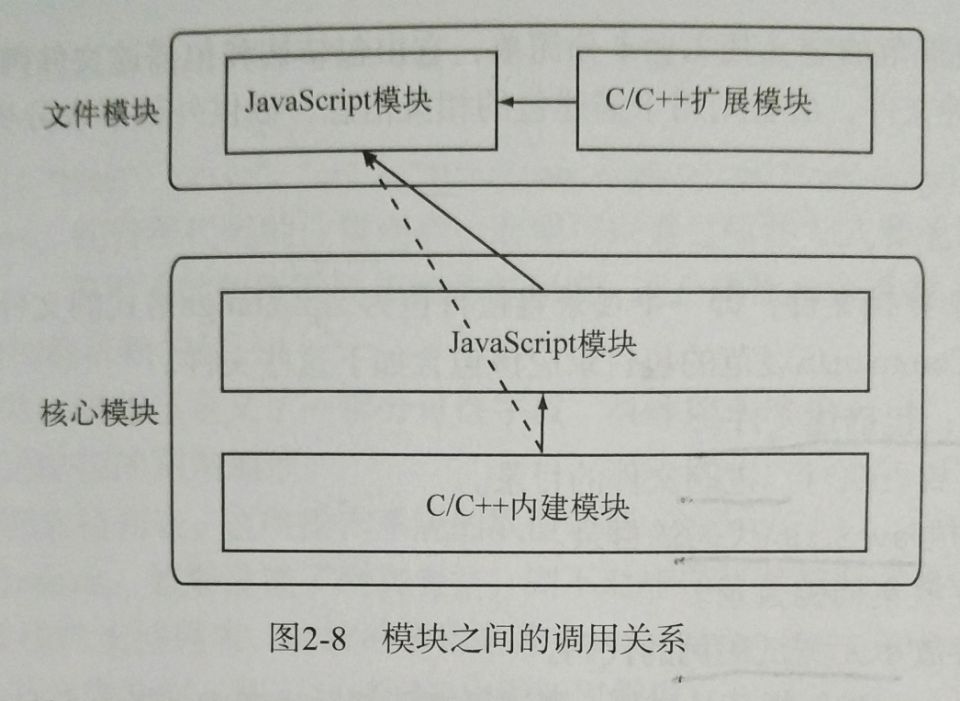
通常来说,在Node中,由JavaScript编写的核心模块依赖于C/C++编写的内建模块。而文件模块一般依赖于核心模块,而不是直接调用内建模块。
Node在启动时候,会生成一个全局变量process,并会提供一个Binding()方法用来协助内建模块。
C/C++扩展模块
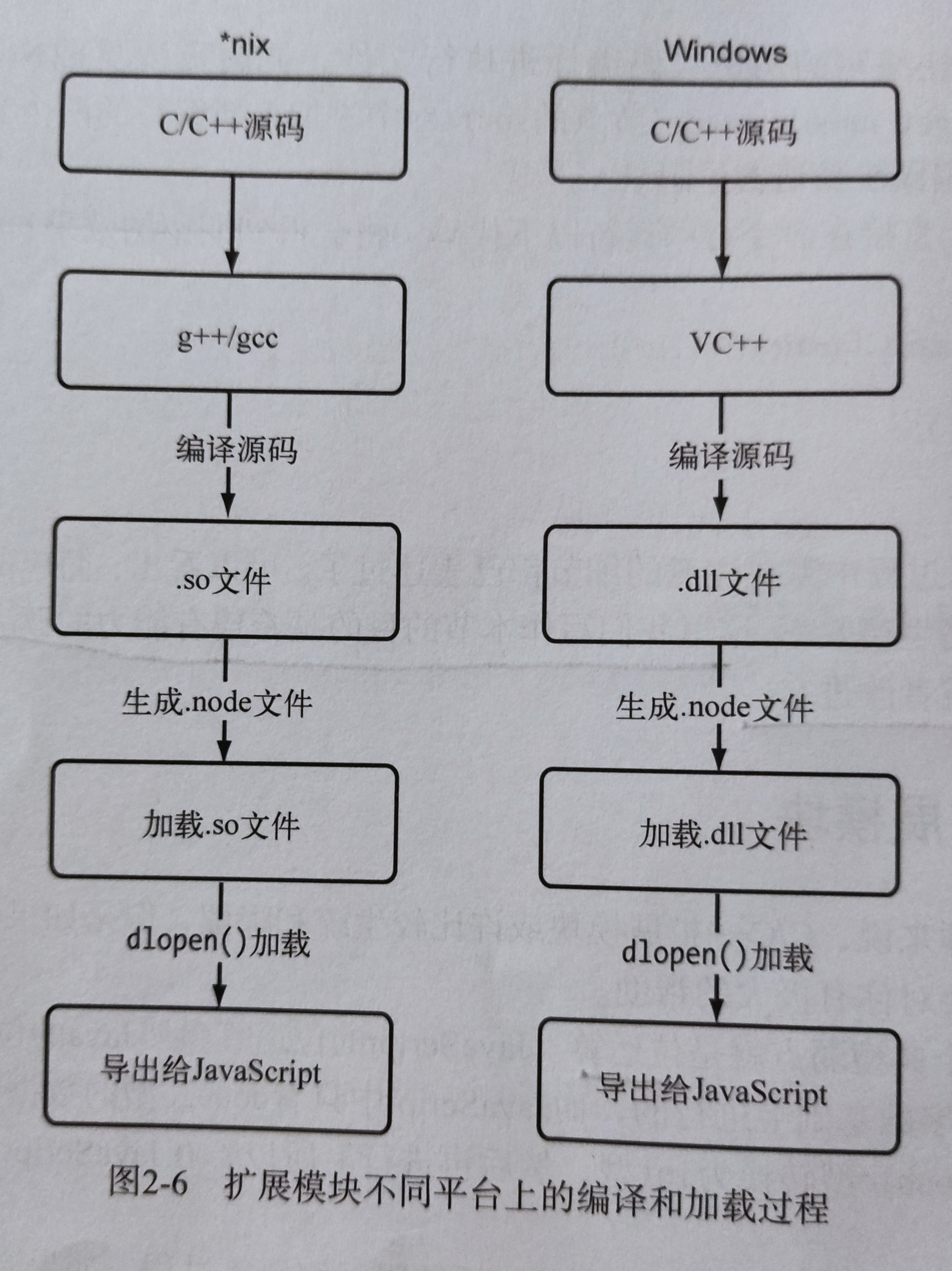
C/C++扩展模块是属于文件模块得一类。C/C++模块通过预编译为.node文件,在调用process.dlopen()方法来加载执行。
注意:.node文件实际上是编译过后得二进制文件,所以在不同平台下是不同的,在Windows下,其就是一个.dll文件,在*nix下,其是一个.so文件,加一个.node是为了看起来更自然。
在dlopen()中,实现了分平台加载.so,.dll的方法。
所以一个不同的.node文件是无法混用的,必须重新在其平台下编译成正确的.node文件。
前提条件
- GYP项目生成工具:Node编译工具,可以通过
npm install -g node-gyp命令安装。 - V8引擎C++库:V8是Node自身动力来源之一。它自身由C++写成,可以实现JavaScript与C++互相调用。
- libuv库:libuv也是Node自身的动力来源之一。其是一个跨平台的一层封装,通过它去调用一些底层操作,比自己在各个平台下编写实现要高效得多。libuv封装得功能包括事件循环、文件操作等。
- Node内部库:写C++模块时,免不了要做一些面向对象得编程工作,而Node自身提供了一些C++代码,比如
node::ObjectWrap类可以用来包装你的自定义类,它可以帮助实现对象回收等工作。 - 其他库:其他存在
deps目录下的库在编写扩展模块时也许可以帮助你,比如zlib,openssl,http_parser等。
C/C++扩展模块的编写
与核心模块的编写不同,普通的扩展模块不需要无须将源代码编译进Node,而是通过dlopen()方法动态加载。所以在编写普通模块时,无须将源代码写入node命名空间,也不需要提供头文件。
例子
编写
JavaScript写法:
1 | exports.sayHello = function(){ |
C++写法:
1 | // hello.cc |
编译
在不同的平台都可以使用GYP工具进行编译。
首先需要编写.gyp项目文件。node-gyp约定.gyp文件为bidning.gyp,其内容示例如下:
1 | { |
然后调用
1 | $ node-gyp configure |
接下来会生成一些其他文件,在*nix平台下,会生成Makefile等文件;在Windows下,则会生成vcxproj等文件。
1 | node-gyp build |
此时gyp会根据平台,分别进行make或vcbuild进行编译。编译完成后,hello.node文件会生成了build/Release目录下。
注意:
Node.js 使用了静态链接库,比如 V8、libuv 和 OpenSSL。 所有的插件都需要链接到 V8,也可能链接到任何其他的依赖项。 通常情况下,只要简单地引入相应的 #include <...> 声明(如 #include <v8.h>),则 node-gyp 将会自动地定位到相应的头文件。 但是也有一些注意事项需要留意:
- 当
node-gyp运行时,它将会检测指定的 Node.js 发行版本,并下载完整的源代码包或只是头文件。
如果下载了完整的源代码,则插件将会具有对完整的 Node.js 依赖项的完全访问权限。 如果只下载了 Node.js 的头文件,则只有 Node.js 公开的符号可用。
- 可以使用
--nodedir标志指向本地的 Node.js 源代码镜像来运行node-gyp。
如果使用此选项,则插件将有权访问全部依赖项。
注意:工具之间存在兼容性问题,最开始我在实验时的版本是:
- Visual Studio -2019
- Node.js -12.14.0
- node-gym -8.0.0
- python -3.9
结果一直报语法错误,示例如下:
1 | Hello.cc |
网上貌似错误经验不多,我折腾了很久,最后决定换以下node版本,这里使用了nvm版本切换工具。转为最新的15.5.1版本,然后就成功构建了。
C/C++扩展模块的加载
得到hello.node文件后,直接通过require()方法来进行标识符解析,路径解析,文件定位,然后加载执行即可。
示例
1 | //main.js |
调用流程
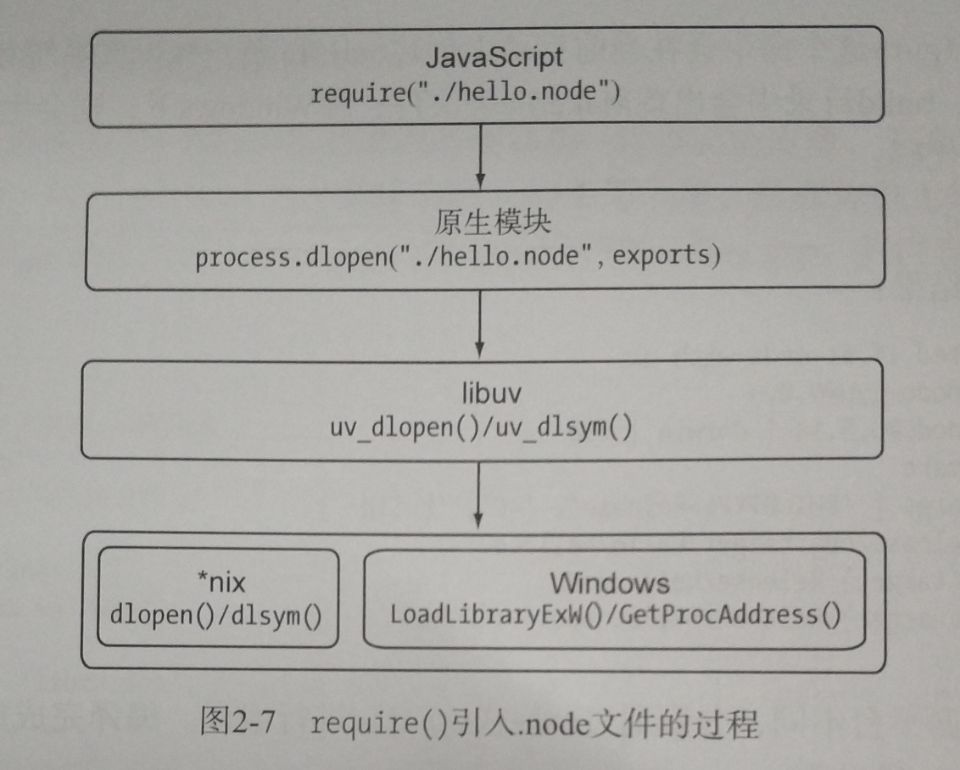
实际上,require()在引入.node文件的过程中,实际上经历了4个层面上的调用。
加载.node文件实际上经历了两个步骤:
- 调用
uv_dlopen()方法去打开动态链接库。 - 调用
uv_dlsym方法找到动态链接库中通过NODE_MODULE宏定义的方法地址。
这两个步骤都是通过libuv库进行封装的:
- 在*nix平台下实际上调用的是dlfcn.h头文件中定义的
dlopen()和dlsym()两个方法; - 在Windows平台则是通过
LoadLibraryExW()和GetProcAddress()这两个方法实现的。他们分别加载.so和.dll文件(即.node文件)
即我们一般不直接调用process.dlopen(),而是通过require()来获取编写的Node模块。在process.md中写到:
process.dlopen(module, filename[, flags])*
module{Object}*
filename{string}*
flags{os.constants.dlopen} *Default:*os.constants.dlopen.RTLD_LAZYThe
process.dlopen()method allows dynamically loading shared objects. It isprimarily used by
require()to load C++ Addons, and should not be useddirectly, except in special cases. In other words, [
require()][] should bepreferred over
process.dlopen()unless there are specific reasons such ascustom dlopen flags or loading from ES modules.
所以最后总结一下Node中各种模块之间的关系则为:
引用
本文大部分参考《深入浅出nodejs》
以及: