
内部原理
理想的非阻塞异步I/O
完美的异步I/O应该是应用程序发起非阻塞调用,无须通过遍历或者事件唤醒等方式轮询,可以直接处理下一个任务,只需要在I/O完成后通过回调将数据传递给应用程序即可。
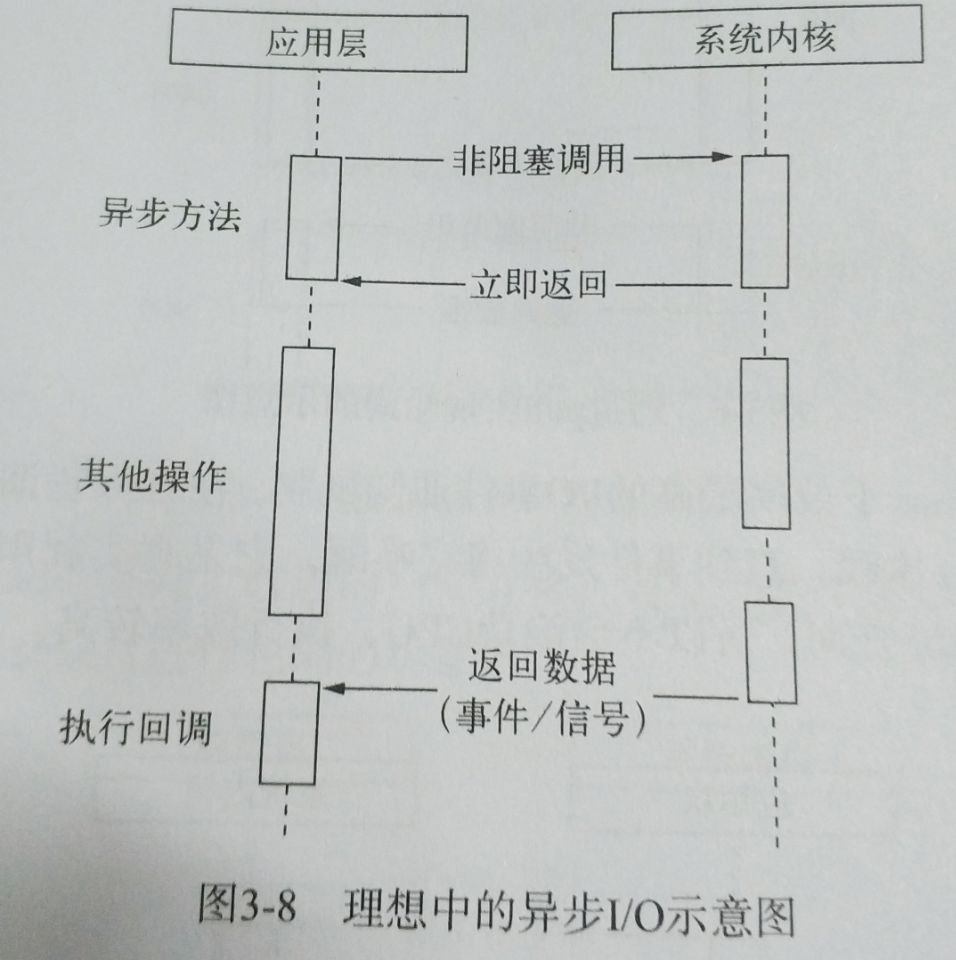
幸运的是:Linux下的AIO就是通过信号或回调来传递数据。
不幸的是:只有Linux下有,而且它还有缺陷-AIO仅支持I/O内核中的O_DIRECT方式读取,导致无法使用系统缓存。
现实的异步I/O
现实更加骨感,但是要达成I/O的目标,并非难事。前面我们将场景限定在了单线程的状态下,实际上使用多线程来模拟异步,就会轻松达成效果了。通过让部分线程进行阻塞I/O或者非阻塞I/O加轮询技术来完成数据获取,让一个线程进行计算处理,通过线程之间的通信将I/O得到的数据及性能传递,就轻松实现了异步I/O。
最初的Node在*nix平台下采用了libeio,libeio实质上依然采用的线程池与阻塞I/O模拟异步I/O。配合libev实现I/O部分,实现了异步I/O。在Node v0.9.3以后,自行实现了线程池来完成异步I/O。
而在Windows平台下,IOCP在某种程度上提供了较为理想的异步I/O:调用异步方法,等待I/O完成之后的通知,执行回调。用户无须考虑轮询。但是它的内部依然是线程池原理,不同之处在于这些线程池是由系统内核接受管理。
由于Windows平台和*in平台的差异,Node提供了libuv作为抽象封装层,使得所有平台兼容性的判断都由这一层来完成,并保证上层的Node与下层的系定义线程池IOCP之间各自独立。Node会在编译期间判断平台,选择性编译*nix或是win目录下的源文件到目标程序中。
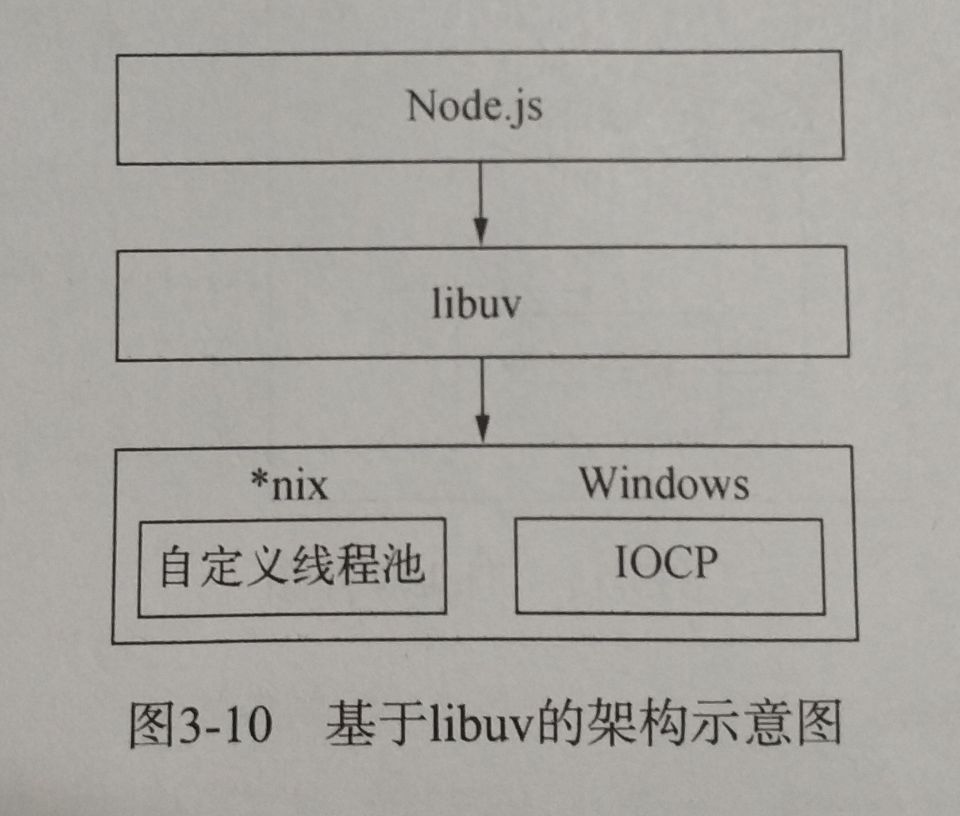
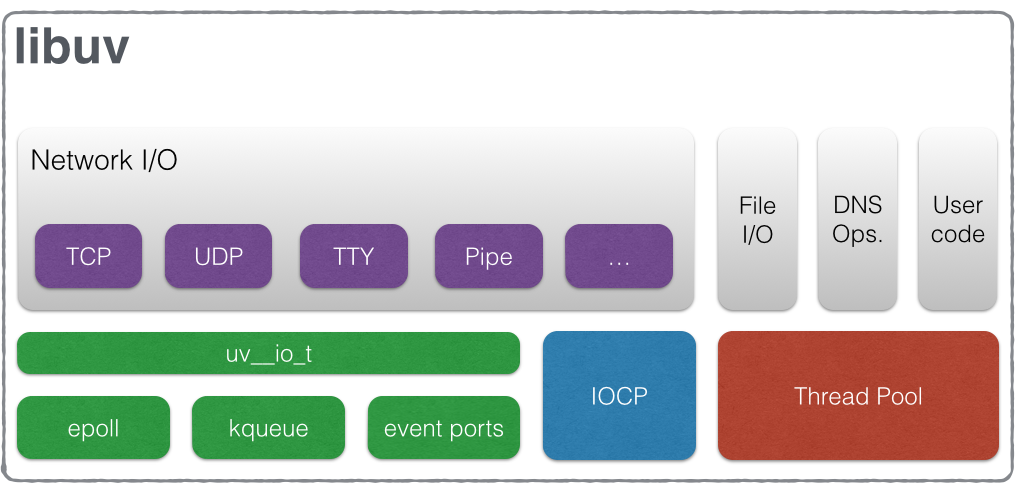
而在*nix平台,对线程池也有不同的方案:
The event loop follows the rather usual single threaded asynchronous I/O approach: all (network) I/O is performed on non-blocking sockets which are polled using the best mechanism available on the given platform: epoll on Linux, kqueue on OSX and other BSDs, event ports on SunOS and IOCP on Windows. As part of a loop iteration the loop will block waiting for I/O activity on sockets which have been added to the poller and callbacks will be fired indicating socket conditions (readable, writable hangup) so handles can read, write or perform the desired I/O operation.
即:
- Linux平台下使用epoll
- OSX和其他BSDs使用kqueue
- SunOS使用event ports
- Windows使用IOCP
值得注意的是:
- 这里的I/O不仅仅只限于磁盘文件的读写。*nix将计算机抽象了一番,磁盘文件,硬件,套接字等几乎所有的计算机资源都被抽象成为了文件,因此这里描述的阻塞和非阻塞的情况同样适用于套接字等。
- 平时我们提及到Node是单线程的,这里单线程仅仅只是JavaScript执行在单线程中。在Node中,无论是*nix或者windows平台,内部完成I/O任务的另有线程池。
执行原理
事件循环
之前在JavaScript宏任务,微任务与Event-loop简单介绍过事件循环的概念。
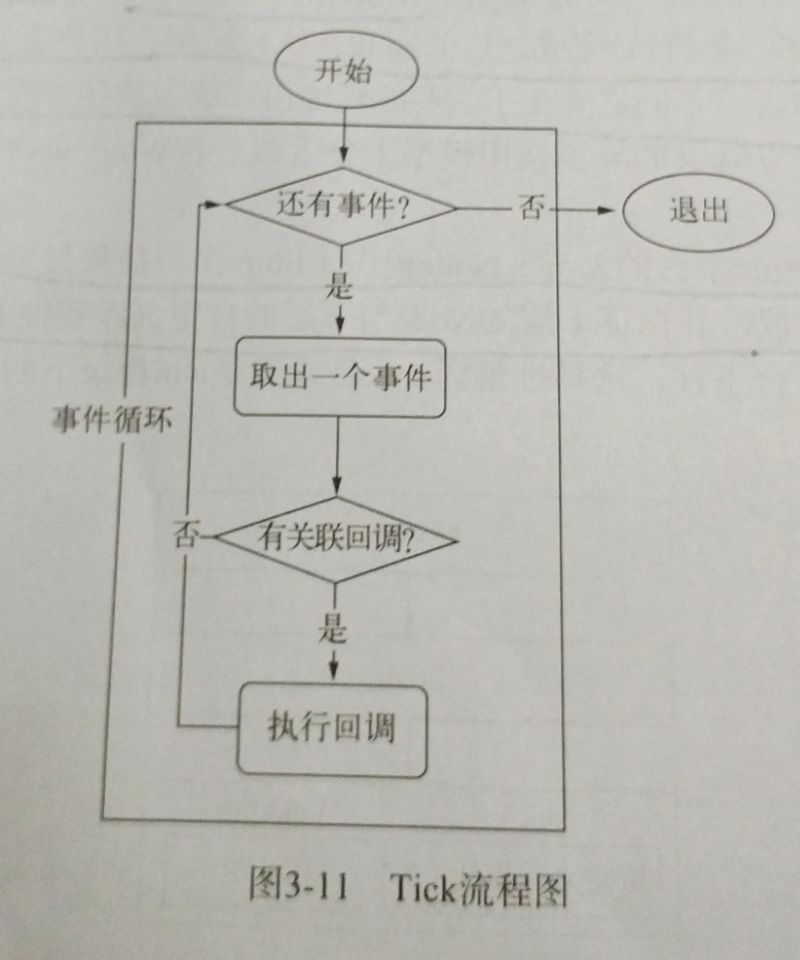
其在进程启动时,Node便会创建一个类似于while(true)的循环,每执行一次循环体的过程我们称为一个Tick,每个Tick的过程就是查看是否有事件待处理。如果有,就取出事件及其相关的回调函数。如果存在关联的回调函数,就执行他们。然后进入下一个循环,如果不再有事件处理,就退出进程。
观察者
在每一个Tick中,都是通过观察者来判断是否有事件需要处理。
每个事件循环有一个或者多个观察者,而判断是否有事件要处理的过程就是向这些观察者询问是否有要处理的事件。
浏览器采用了类似的机制。事件可能来自用户的点击或者加载某个文件时产生,而这些产生的事件都有对应的观察者。在Node中,事件主要来源于网络请求,文件I/O等,这些事件对应的观察者有文件I/O观察者,网络I/O观察者等。观察者将事件进行了分类。
事件循环是一个经典的生产者/消费者模型。异步I/O,网络请求等则是网络事件的请求者,源源不断的为Node提供不同类型的事件,这些事件被传递到对应的观察者那里,事件循环则从观察者那里取出事件并处理。
这里用到了观察者模式,在设计模式5-发布-订阅模式(观察者模式)详细介绍过。
请求对象
在异步请求回调中,从JavaScript发起调用到内核执行完I/O操作的过渡过程中,存在一种中间产物,它叫做请求对象。
下面以fs.open()作为例子,来看一下其源代码:
1 | function open(path, flags, mode, callback) { |
fs.open()是根据指定的路径和参数去打开一个文件,从而得到一个文件描述符,这是后续所有I/O操作的初始操作。从代码可以看出,JavaScript层面的代码是通过调用C++核心模块进行下层的操作。其执行流程如下:
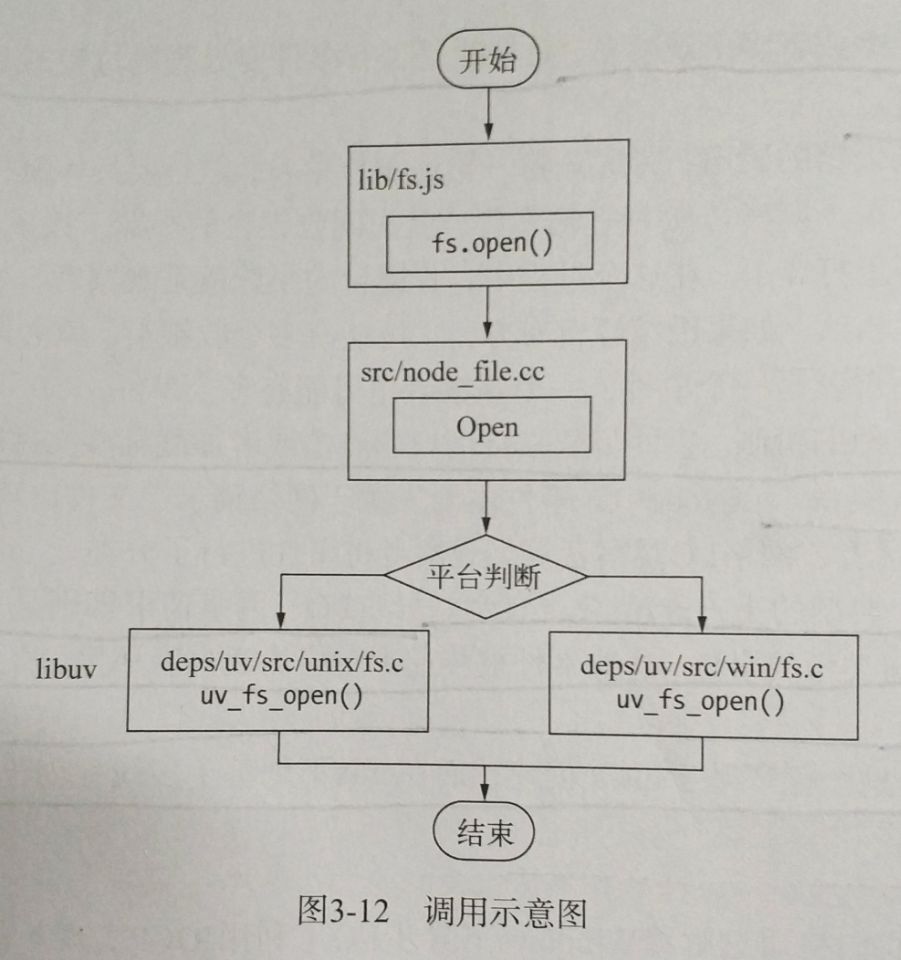
这里是JavaScript典型的调用方法:
- 从JavaScript调用Node的核心模块
- 核心模块调用C++内建模块
- 内建模块通过libuv进行系统调用
在libuv中,实质上调用了uv_fs_open()方法。在uv_fs_open()方法中,调用了uv_fs_req_init,将传入的参数添加到**uv_fs_t请求对象**上。从JavaScript层传入的参数和当前方法都被封装在这个请求对象中,其中我们最为关注的回调函数被设置在这个对象的cb上属性上:
1 | INLINE static void uv_fs_req_init(uv_loop_t* loop, uv_fs_t* req, |
对象封装完毕后,在Windows下,则调用QUEUE_FS_TP_JOB()=>uv__req_register()=>QUEUE_INSERT_TAIL()方法将这个uv_fs_t对象推入,线程池中等待执行,该方法的代码如下:
1 | QUEUE_INSERT_TAIL(&(loop)->active_reqs, &(req)->active_queue); |
该方法接受2个参数:
&(loop)->active_reqs:要执行的方法的引用。&(req)->active_queue:事件循环队列。
至此,JavaScript调用立即返回,由JavaScript底层发起的异步调用的第一阶段就此结束。JavaScript线程可以继续执行当前的后续操作。当前的I/O操作在线程池中等待执行,不断是否阻塞I/O,都不会影响JavaScript线程的后续操作,如此就达到了异步的目的。
(在libuv0.1中,Windows使用的是QueueUserWorkItem()API,而在Unix使用的是默认4个的线程池,而在1.0版本中,在Windows与Unix统一了标准,都是用了线程池,更新公告如下:)
Threadpool changes
~~~~~~~~~~~~~~~~~~
In libuv 0.10 Unix used a threadpool which defaulted to 4 threads, while Windows used the
QueueUserWorkItemAPI, which uses a Windows internal threadpool, which defaults to 512threads per process.
In 1.0, we unified both implementations, so Windows now uses the same implementation Unix
does. The threadpool size can be set by exporting the
UV_THREADPOOL_SIZEenvironmentvariable. See :c:ref:
threadpool.
请求对象时异步I/O过程中的重要中间产物,所有的状态都保存在这个对象中,包括送入线程池等待执行以及I/O操作完毕后的回调处理。
执行回调
组装好请求对象,送入I/O线程池等待执行,实际上完成了异步I/O第一部分,回调通知是第二部分。
线程池中的I/O操作调用完毕之后,会将获取的结果存储在req->result属性上,然后调用PostQueuedCompletionStatus()通知IOCP,告知当前对象操作已经完成:
1 | PostQueuedCompletionStatus(loop->iocp, 0, 0, NULL); |
PostQueuedCompletionStatus()方法的作用是向IOCP提交执行状态,并将线程归还给线程池。通过PostQueuedCompletionStatus()方法提交的状态,可以通过GetQueueCompletionStatus()提取。
在这个过程中,其实还动用了事件循环的I/O观察者。在每次Tick的执行中,它会调用IOCP相关的GetQueueCompletionStatus()方法检测线程池中是否有执行完的请求,如果存在,会将请求对象加入到I/O观察者的队列中然后将其作为事件处理。
I/O观察者回调函数的行为就是取出请求对象的result属性作为参数,取出cb属性作为方法,然后调用执行,以此达到调用JavaScript中传入的回调函数的目的。
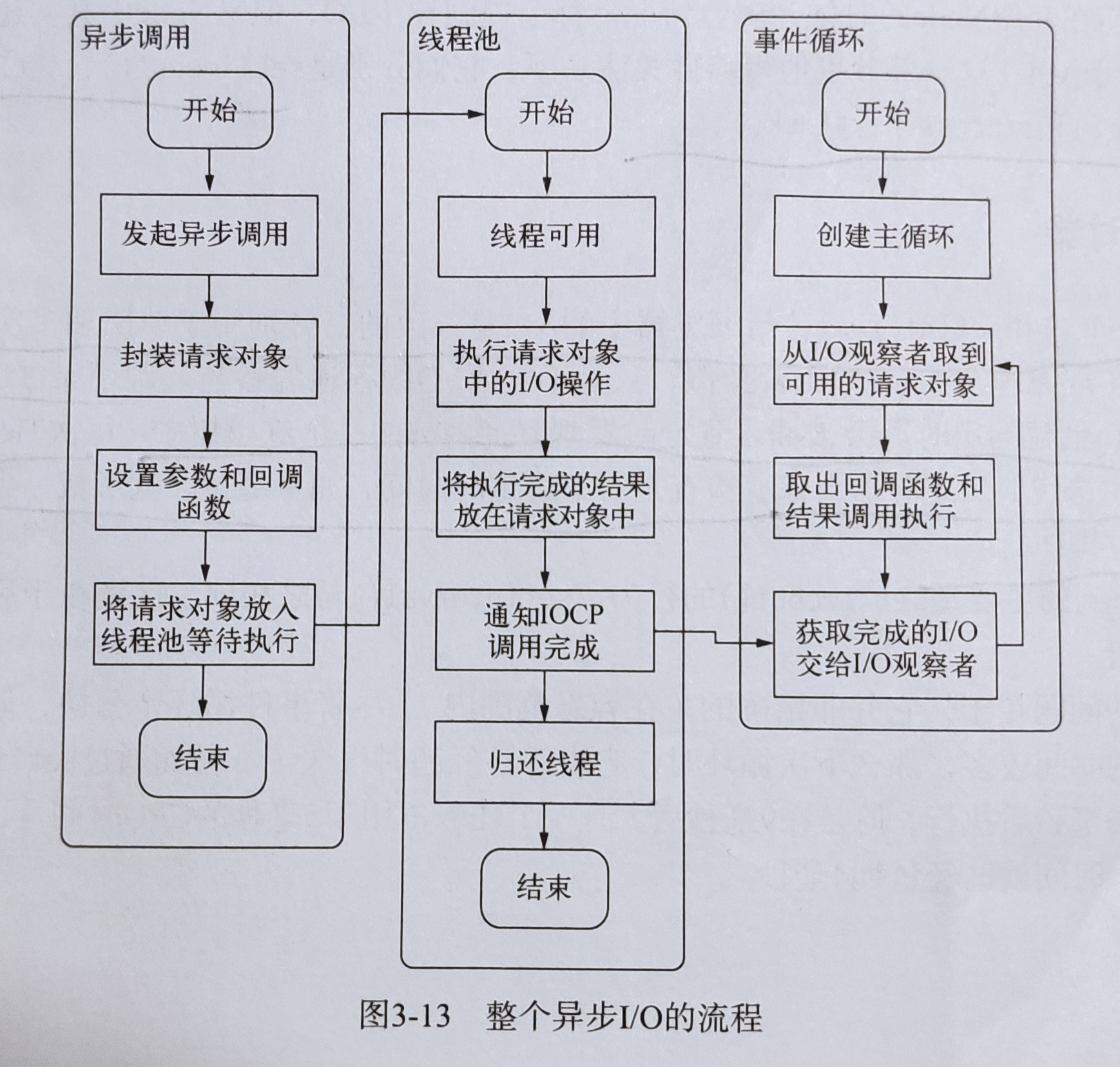
事件循环、观察者、请求对象、I/O线程池这四者共同构成了Node异步I/O模型的基本要素。
非I/O的异步API
定时器
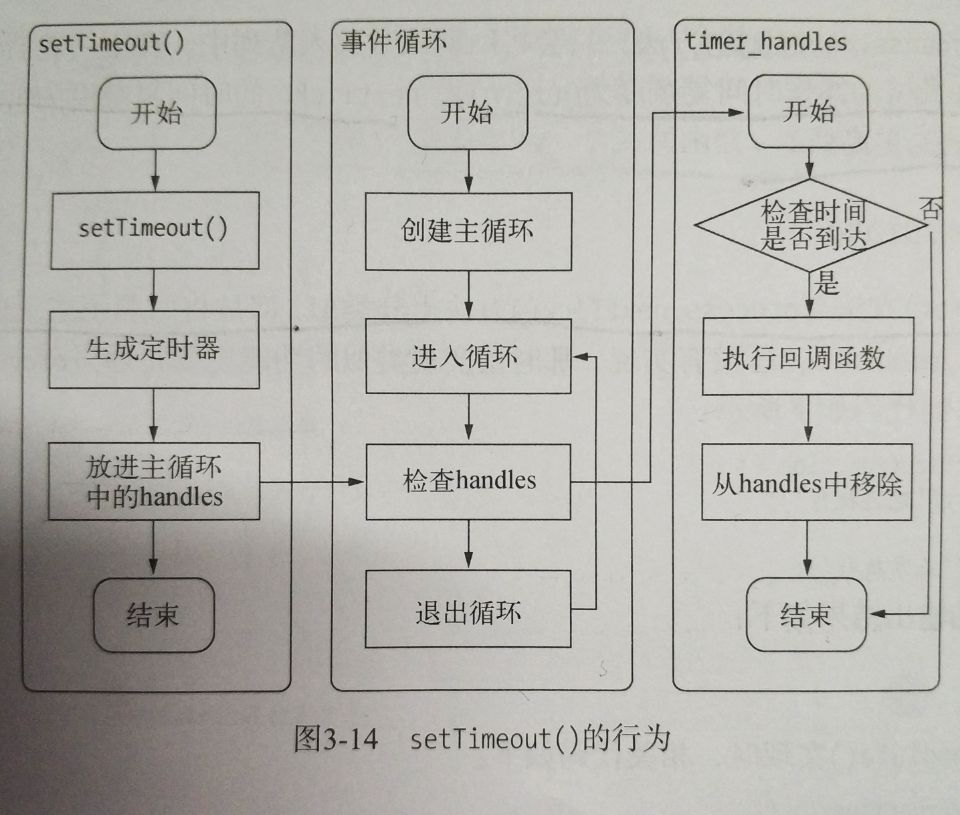
setTimeout()和setInterval()与浏览器中的API是一致的,分别用于单词和多次定时器执行任务。他们的实现与异步I/O相似,只是不需要I/O线程池的参与。调用setTimeout()或者setInterval()创建的定时器会被插入到定时器观察者内部的一个红黑树。每次Tick执行时,会从红黑树迭代取出定时器对象,检查是否超过定时时间,如果超过,就会形成一个事件,它的回调函数会立即执行。
众所周知,定时器并不是那么准确其原因也在于事件循环,虽然事件循环非常快,但是如果某个循环占用的时间比较多,那么下次循环时,它也许已经超时很久了。
process.nextTick()
process.nextTick() 会添加 callback 到下一个时间点队列。 在 JavaScript 堆栈上的当前操作运行完成之后,且允许事件循环继续之前,此队列会被完全耗尽。
此方法与setTimeout比起来,更加轻量级,因为不需要动用红黑树,创建定时器对象和迭代等操作。其代码如下:
1 | // `nextTick()` will not enqueue any callback when the process is about to |
每次调用process.nextTick()方法只会将回调函数放入队列中,在下一轮Tick时取出执行。定时器采用红黑树的操作时间复杂度为O(lg(n)),nextTick()的时间复杂度为O(1)。
setIMmediate()
setImmediate()方法与process.nextTick()方法类似,都是将回调函数延迟执行。但是两者之间还是有一定的区别:
process.nextTick()方法优先级要高于setImmediate()。process.nextTick()的回调函数保存在一个数组中,setImmediate()的回调函数函数保存在链表中。process.nextTick()在每轮循环中执行链表中的一个回调函数,而setImmediate()在每轮循环中执行链表中的一个回调函数。
其优先级不同的原因在于:事件循环对观察者的检查是有先后顺序的,process.nextTick()属于idle观察者,setImmediate()属于check观察者。在每轮循环中,idle观察者先于I/O观察者,I/O观察者先于check观察者。
例子
1 | process.nextTick(function(){ |
结果如下:
正常执行
nexiTick延迟执行1
nexiTick延迟执行2
setImmediate延迟执行1
强势插入
setImmediate延迟执行2
异步编程的优势与难点
优势
Node带来的最大特性莫过于事件驱动的非阻塞模型。非阻塞I/O可以使CPU与I/O并不相互依赖等待,让资源得到更好的利用。
Node利用事件循环的方式,JavaScript线程池像一个分配任务和处理结果的管家,I/O线程池中的各个I/O线程都是小二。负责完成分配来的任务,小二与管家之间互不依赖,所以可以保持整体的高效率。但是由于JavaScript是单线程,所以,这个系统的极限就是JavaScript线程。换言之,Node为了解决编程模型中阻塞I/O的性能问题,采用了单线程模型,这导致Node更像是一个处理I/O密集问题的能手,而CPU密集型取决于管家的能耐如何。
而通过C++写出来的V8虽然相较于原生C++多了一个编译过程。但是性能仍然可以逼近顶尖。
难点
异常处理
在传统的同步编程中,通常使用Java的try/catch/final语句块来进行异常捕获。但是这对于异步编程并不适用。因为在之前提到过,异步I/O主要分为两个阶段:请求提交和处理结果。这两个阶段中间有事件循环机制,两者彼此不相关联。异步方法则通常在第一个阶段请求后立即返回,因为异常不一定发生在这个阶段,try...catch...不会生效。
在Node中为了解决这个问题,一般形成了一个约定,将异常作为回调函数的第一个实参传回,如果为空值,则表明异步回调没有抛出。在这个约定中,我们在编写的异步方法上。也必须取遵循这样几个原则:
原则一:必须执行调用者传入的回调函数。
原则二:正确传递回异常供调用者判断。
示例代码中:
1 | let async = function(callback){ |
另外可能出现的错误写法是:
1 | try{ |
上述代码的意图是捕获是捕获JSON.parse()中可能出现的异常,但是却不小心包含了用户传递的回调函数。这意味着如果回调函数中有异常抛出,将会进入catch()代码块中执行,于是回调函数将会被执行两次。这样显然不是预期的结果,可能导致业务混乱。正确的代码应为✔:
1 | try{ |
另外还有一种方法就是将错误时执行的回调一并传递给异步函数,在异步函数出错时直接调用错误的回调函数就行了,而且现在普遍采用这种方式,典型的比如Promise.then(suc, fail),或者Axios等框架的设计。
简单的例子如下:
1 | let async = function(success, fail){ |
如果需要更多参数,可以把函数参数设置为一个对象,现在普遍是这么做的。
函数嵌套过深
这也是Node开发被人诟病最多的地方。在现代前端工程化开发中,由于采用Node作为支持,特别是在网络请求中,经常会出现嵌套过深的问题,如:
1 | import {req1, req2, req3} from 'api.js' |
这样的问题目前仍然困扰着开发人员。
async函数解决办法
但是ES6的async函数为我们提供了一个解决该问题的途径,它可以使我们像编写同步代码一样编写异步代码,其本质是Promise的语法糖。
async函数在定义的时候需要使用async关键词,如下:
1 | async function req1(){ |
async函数会返回一个Promise对象,可以使用then方法获取结果。当函数执行的时候,一旦遇到await就会先返回,等到异步操作完成,再接着执行函数体内后面的语句。
具体的用法可以参考ECMAScript 6 入门
用async可以将上面请求的代码改写为:
1 | import {req1, req2, req3} from 'api.js' |
目前的问题有两个(第一个也许不算):
await命令只能在async函数中使用,而async返回的是一个promise对象,也就是说,我们必须最后再调用一个then()方法用于获取结果。(或许这不算什么问题,至少让嵌套次数减少到一次)- 兼容性问题:
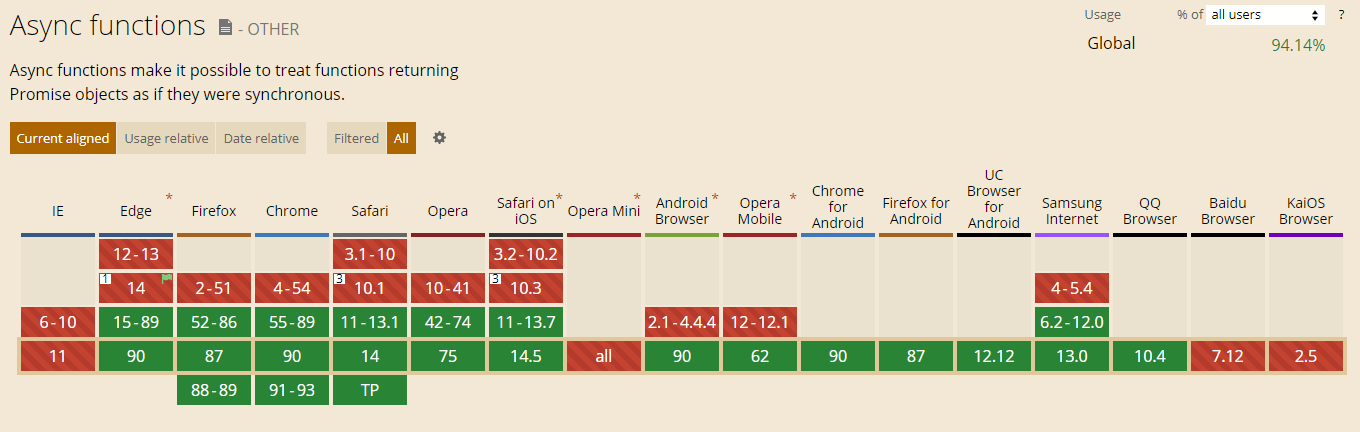
可以看出,IE完全不支持,chrome也到55版本才支持,所以兼容性是一个很大的问题。
但是如果在工程化的前端开发中,由于多了预编译过程,所以使用ES6的语法会被转义为ES5的可接受代码。比如vue-cli中,在初始化项目时就包含了babel。
阻塞代码
在Node中还有一个问题是,没有sleep()这样的线程沉睡功能,能用做延时操作的只有setInterval和setTimeout。但这两个函数并不能阻塞后面的代码执行。
很多人会使用while方式实现阻塞,但是由于Node是单线程,所以使用while会持续占用CPU进行判断,这与真正的线程沉睡相差甚远我,完全破环了事件循环的调度。官方推荐的是使用setTimeout来实现,但是问题在于,setTimeout无法阻塞后面的代码运行。
setTimeout实现
实现如下:
1 | setTimeout(() => { |
这里虽然定时器内的代码会被延迟执行,但是后面的otherFunc1(),otherFunc2()都会立即执行,这样不符合我们印象中的sleep()
setTimeout配合async实现
刚才我们讲过async会一直等待await后的语句执行完毕,才会执行后面的语句,所以我们可以利用这个点实现sleep功能。
1 | function sleep(interval) { |
当然,还有一个问题就是,我们使用sleep()的函数必须定义为async函数,也就是说,外部调用该函数时,也必须定义为async,或者处理Promise。
异步编程的解决方案
事件发布订阅模式
事件监听器模式是一种广泛应用于异步编程的模式,是回调函数的事件化,又称为发布订阅模式。具体实现可以参见之前写过的设计模式5-发布-订阅模式(观察者模式)。
Node自身提供的event模块是发布订阅模式的一个简单实现,Node中的部分模块抖继承自它,这个模块比前端浏览器中的大量DOM事件简单,不存在事件冒泡,也不存在preventDefault(),stopPropagation()和stopImmediatePropagatiom()等控制事件传递的方法(在14.5版本中,已经写出了Event类,实现了event.bubbles,event.cancelBubble()等方法,但是还没有实现,等待后面官方实现吧)。它具有addListener/om(),once(),removeListener(),removeAllListeners()和emit()等基本的事件监听模式的方法实现。时间发布/订阅模式的操作比较简单,示例代码如下:
1 | const EventEmitter = require('events'); |
事件发布订阅模式一般来说有两个用处:
- 业务逻辑解耦,事件发布者无须关注订阅的监听器如何实现业务逻辑,甚至不用关心有多少个监听器的存在,数据通过消息的方式可以很灵活地传递。
- 另一个角度来看,事件监听模式也是一种钩子(hook)机制,利用钩子导出内部数据或者状态给外部的调用者。
期中HTTP请求时经典场景:
1 | const postData = querystring.stringify({ |
在HTTP请求的代码种,程序员只需要将视线放在error,data,end这些业务事件点上即可,至于内部的流程如何,无需过多关注。
值得一提的是:Node对事件发布/订阅的机制做了一些额外的处理,这大多是基于健壮性而考虑的。
如果对一个事件添加超过了10个监听器,将会得到一条警告。这一处设计于Node自身单线程运行有关,设计设认为太多的监听器太多可能导致内存泄漏,所以会存在这样一条警告。
1
(node:4004) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 event listeners added to [MyEmitter]. Use emitter.setMaxListeners() to increase limit
调用
emitter.setMaxListeners(),参数设为0或者Infinity表示不限制监听器的数量。另一方面,由于时间发布会引起一系列监听器执行,如果事件相关的监听器过多,可能存在过多占用CPU的情景。为了处理异常,
EventEmitter对象对error事件进行了特殊对待。如果运行期间的错误出发了error事件,EventEmitter会检查是否有对error事件添加过监听器。如果添加了,这个错误会交由监听器处理,否则这个错误会作为异常抛出。如果外部没有捕获这个异常,将会引起线程退出。一个健壮的EventEmitter示例应该对error事件进行处理。
Promise/Deferred模式
使用时间的方式时,执行流程需要被余预先设定。即便是分支,也需要预先设定,这是由发布/订阅模式的运行机制所决定的。下面为普通的Ajax调用:
1 | $.get('/api', { |
在上面的异步调用中,必须严谨的设置目标。那么是否有一种先执行异步调用,延迟传递处理的方式呢?答案就是Promise/Deferred模式。
Promise/Deferred模式最早在JavaScript框架中出现于Dojo的代码中,被广为所知则是来自jQuery1.5版本,该版本几乎重写了Ajax部分,是的调用Ajax可以通过错如下的形式。
1 | $.get('./api') |
这使得即使不调用success(),error()等方法,Ajax也会执行。
在原始的API中,一个事件只能处理一个回调,而通过Deffered对象,可以对事件加入任意的业务处理逻辑,示例代码如下:
1 | $.get('/api') |
Promise/Deffered模式在2009年时被Kris Zyp抽象为一个提案,发布在CommonJS规范中。随着使用Promise/Deffered模式的应用逐渐增多,Promise/Deffered提案已经抽象出Promise/A、Promise/B、Promise/D等典型的模式。随后Promise/A规范已经成为EcmaScript的官方规范。ES6中的Promise规范即为Promise/A规范。
具体的Promise原理和手写可以看我的这两篇文章:
引用
本文大部分参考《深入浅出nodejs》以及Node官网