
输入与输出流
在Java API中,输入流是一个可以读入字节的对象;输出流是一个可以写如字节的对象。这些字节的来源和目的地可以是文件、网络甚至是内存块。
抽象类InputStream和OutputStream构成了输入/输出类层次结构的基础。(注意与上一节的流操作完全不同)
InputStream
InputStream是输入流,即通过文件等获取一个InputStream的子类。然后通过其API获得输入流中的内容。其主要API如下:
abstract int read():从数组中读取一个字节,并返回该字节。结尾时返回-1。int read(byte[] b):读入一个字节数组,并返回实际读入的字节数,结尾时返回-1。其最多读入b.length个字节。int read(byte[] b, int off, int len):读取len个字节存入b数组,而且从b数组的第off个位置开始写入。byte[] readNBytes(int len):与2相同,不过该API只有在读取到len个字节、流结束或发生错误时才会返回。否则会一直阻塞。int readNBytes(byte[] b, int off, int len):3+4.byte[] readAllBytes():读取流中所有的字节到一个数组。本质是调用return readNBytes(Integer.MAX_VALUE);long transferTo(OutputStream out):将当前输入流中的所有字节传送到给定的输出流,返回传递的字节数。这两个流都不应该处于关闭状态。long skip(long n):在输入流中跳过n个字节,返回实际跳过的字节数(遇到输入流的结尾,则可能小于n)。int available():返回在不阻塞的情况下可获取的字节数。void close():关闭这个输入流。void mark(int readlimit):在输入流的当前位置打一个标记(并非所有的流都支持整个标记)。如果从输入流中已经读入的字节多余readlimit个,则这个流允许忽略整个标记。void reset():返回到最后一个标记,随后对read的调用将重新读入这些字节。如果当前没有任何标记,则这个流不被重置。void markSupported():检测当前流是否支持打标记。
OutputStream
abstract void write(int n):写出一个字节的数据。void write(byte[] b):将b中的字节写入到输出流中。void write(byte[] b, int off, int len):与2相同,不过是从b的off位置开始,写出len个字节。void close():冲刷并关闭输出流。void flush():冲刷输出流,即将所有缓冲的数据发送到目的地。
Reader/Writer
Java Stream相关类是用来处理字节流的,但不适合用来字符流.因为一个字节是8bit,而一个字符是16bit.字符串是由字符组成,字符串类型天然处理的是字符而不是字节.更重要的是,字节流无法知道字符集及其字符编码.Java中可以用Reader/Writer相关类来处理字符.
而Reader/Writer类的基本方法与InputStream/OutputStream基本一致。
如:
1 | abstract int read(); |
read方法将返回一个Unicode码元(一个在0-65535之间的整数),或者在碰到文件结尾的时返回-1。write方法在被调用时,需要传递一个Unicode码元。
所有输入输出流及其关系
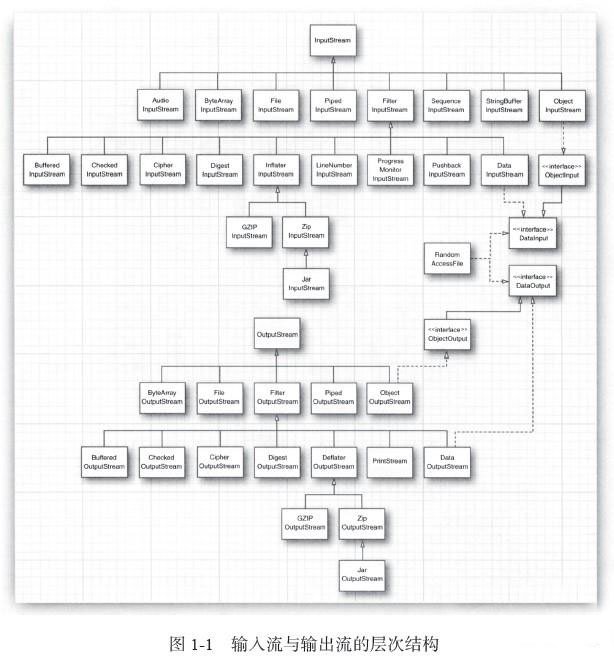
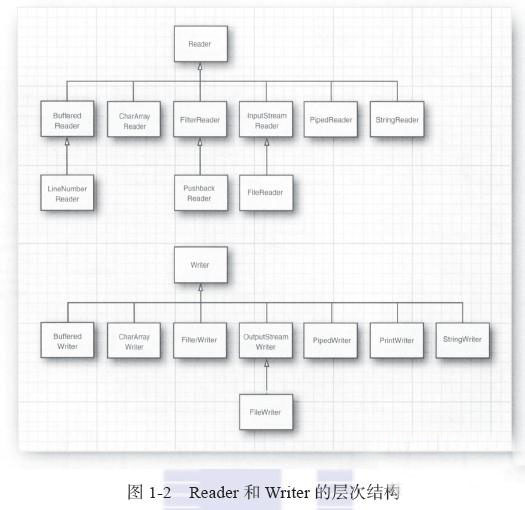
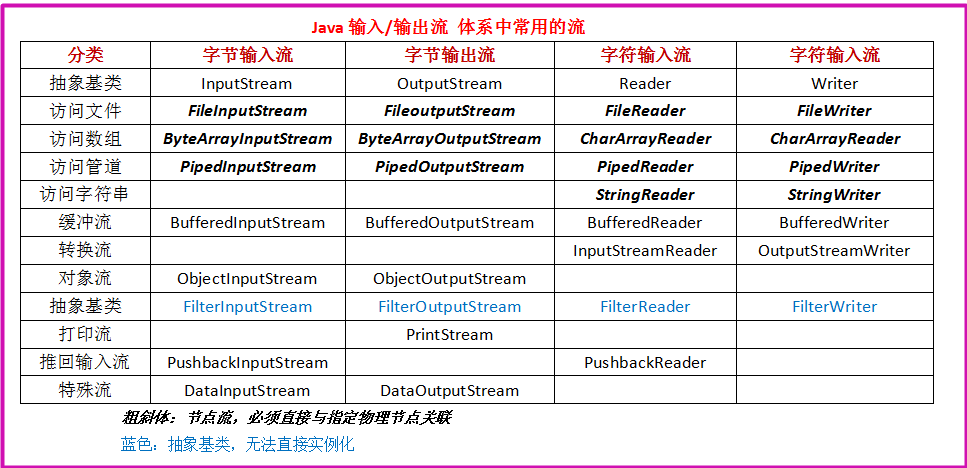
组合输入/输出流过滤器
在Java中,不同的输入输出类有自己的职能。
例如,
FileInputStream和FileOutputStream可以提供一个磁盘文件上的输入输出流,并且只需要想起构造器提供文件名或晚间的完整路径名。如:1
var fin = new FileInputStream("employee.dat");
但是两个类与抽象类
InputStream/OutputStream一样,这些类只支持在字节级别上的读写。即只能从fin对象读入字节或字节数组:1
byte b = (byte) fin.read();
DataInputStream和DataoutputStream能够读入数字,如:1
2DataInputStream din = ...;
double x = din.readDouble();但是
DataInputStream和DataoutputStream却没有任何能够读取文件的方法。
这正是Java的流的设计机制,即一个流只负责对应的单一功能。需要复合功能时(如:从文件中读取数字),则将负责不同职能的流组合起来已到达效果。
例如:从文件中读取一个数字:
1 | FileInputStream fin = new FileInputStream("employee.dat"); |
这样的流可以多层嵌套来实现更多的效果。
例如:输入流在默认情况下是不被缓冲区缓存的,也就是说,每个对read的调用都会请求操作系统再分发一个字节。而BufferedInputStream可以为输入流提供一个缓冲区,则读取会更加高效。则代码如下:
1 | DataInputStream din = new DataInputStream( |
注意,我们把DataInputStream置于构造器链的最后,这是因为我们希望使用DataInputStream的方法,并且希望它们能够使用带缓冲区机制的read方法。
当我们需要调用中间输入流的方法时,我们可以在传递参数时对外部引用进行赋值。如:
1 | BufferedInputStream bbin = null; |
一般来说输入输出流的顺序并不是特别重要,主要是最外层和最内层的输入输出流,因为需要调用这两个的API和构造器
读写文本文件
在保存数据时,可以选择二进制格式或文本格式。
如,整数1234存储为二进制时,会被写为由字节00 00 04 D2构成的格式(十六进制表示法)。而被存储为文本格式时,则会被写入字符串”1234“。
二进制格式的I/O高速且高效,但是并不适合人类阅读。
写出文本输出
对于文本的输出,可以使用PrintWriter。这个类拥有以文本格式打印字符串和数字的方法。
为了输出到打印写出器,需要使用与System.out时相同的print、println和printf方法。可以用其来打印各种数据结构。
例如:
1 | PrintWriter out = new PrinterWriter("employee.txt", StandardCharsets.UTF_8); |
其将会把字符Harry Hacker 75000.0输出到写出器out,之后这些字符将会被转换为字节并最终写入employee.txt
与System.out一样,println在行中添加了对目标系统的来说恰当行结束符(Windows系统是"\r\n",UNIX系统是"\n")。
PrinterWriter第二个参数是确定是否为自动冲刷模式,如果为true,则打开自动冲刷模式。那么只要println被调用,缓冲区中的所有字符都会被发送到目的地。默认是false。
读取文本输入
通过Files类
一般现在使用Java7引入的Files类来读取文本内容。
例如:
读取小文件直接到String:
1
2
3Path path = Path.of("./a.txt");
Charset charset = StandardCharsets.UTF_8;
String content = Files.readString(path, charset);按行读取文件
1
List<String> lines = Files.readAllLines(path, charset);
如果文件过大,还可以处理为
Stream对象1
2
3try(Stream<String> lines = Files.lines(path, charset)){
...
}
通过Scanner来实现
也可以通过Scanner类来读取文件,虽然现在主要通过new Scanner(System.in)来读取控制台输入。
Scanner类有多种重载:
private Scanner(Readable source, Pattern pattern)public Scanner(Readable source)public Scanner(InputStream source)public Scanner(InputStream source, String charsetName)public Scanner(InputStream source, Charset charset)public Scanner(File source)public Scanner(File source, String charsetName)public Scanner(File source, Charset charset)private Scanner(File source, CharsetDecoder dec)public Scanner(Path source)public Scanner(Path source, String charsetName)public Scanner(Path source, Charset charset)public Scanner(String source)public Scanner(ReadableByteChannel source)public Scanner(ReadableByteChannel source, String charsetName)public Scanner(ReadableByteChannel source, Charset charset)
可以看出,其可以从实现了Readable接口的对象、InputStream、File、Path、String或者实现了ReadableByteChannel接口的对象来读取文本。
下面演示从Path和File中读取
例如:
1 | Path path = Path.of("a.txt"); |
通过BufferedReader
在早期的Java版本中,处理文本输入的唯一方式就是通过BufferedReader类。它的readLine方法方法将产生一行文本,在没有更多输出时,返回null。
例如代码如下:
1 | InputStream inputStream = ...; |
读写二进制文件
DataInput和DataOutput接口
DataOutput接口定义了下面用于以二进制格式写数组、字符、Boolean值和字符串的方法:
writeCharswriteBytewriteIntwriteShortwriteLongwriteFloatwriteDoublewriteCharwriteBooleanwriteUTF
如,writeInt总是将一个整数写出为4字节的二进制数量值,而不管它有多少位。writeDouble总是将一个double值写出为8字节的二进制值(取决与处理器类型)。
这样产生的结果并非人可阅读的,但是对于给定类型的每个值,使用的空间都是相同的,而且将其都会也比解析文本要更快。
writeUTF方法使用修订版的8位Unicode转换格式写出字符串。这中方式与直接使用标准的UTF-8编码不一样,其中,Unicode码元序列首先用UTF-8表示,其结果之后使用UTF-8规则进行编码。修订后的编码方式对于编码大于OXFFFF的字符的处理有所不同,这是为了向后兼容在Unicode还没有超过16位时构建的虚拟机。这种编码应该在只用于Java虚拟机的字符串时使用。
为了读回数据,可以使用在DataInput接口中定义的下列方法:
readIntreadShortreadLongreadFloatreadDoublereadCharreadBooleanreadUTF
具体来说,可以使用实现了DataInput和DataOutput接口的DataInputStream和DataOutputStream类。
其分别继承了FilterInputStream和FilterOutputStream类。
所以也分别实现了其中的read和write方法。
例如:
1 | try { |
随机访问文件
RandomAccessFile类可以在文件中的任何位置读取或写入文件。磁盘文件都是随机访问的,但网阔套接字的输入/输出流却不是。
可以直接通过构造器来获得一个文件的RandomAccessFile引用。而第二个参数为模式。具体如下:
| 值 | 解释 |
|---|---|
| r | 只能读文件,写时会抛出IOException。 |
| rw | 可读可写,如果不存在将会尝试创建。 |
| rws | 可读可写,并且每次更新文件时都将内容和元信息同步更新到文件中。 |
| rwd | 可读可写,并且每次更新文件时都将内容同步更新到文件中。 |
随机访问我呢见有一个表示下一个将被读入或写入的字节所处位置的文件指针,
seek方法可以用来将这个文件指针设置到文件中的任意字节位置。seek接受一个long整型数。
getFilePointer方法将返回文件指针的当前位置。
RandomAccessFile类同时实现了DataInput和DataOutput接口。因此可以调用之前提到的readInt/writeInt或readChar/writeChar。
例如,我们要存储一个对象为二进制,我们可以分别确定对象的每个成员变量字节数进而确定每个对象的字节数。
整数和浮点数在二进制格式中都具有固定的尺寸。对于字符串,可以固定长度,不够的话填0来解决。对于含有以下成员的对象:
- 1String-40字符, 80个字节。用于名词。
- 1double=8字节。用于薪水。
- 3 int=12字节。用于日期。
则整体包含100个字节。
则插入一个对象为:
1 | int n = 3; |
ZIP文档
ZIP文档(通常)以压缩格式存储了一个或多个文件,每个ZIP文件都有一个头。包含注入每个文件名字和所使用的压缩方法等信息。在Java中,可以使用ZipInputStream来读入ZIP文档。
读取ZIP文档
而getNextEntry方法就可以返回一个描述这些项的ZipEntry对象。在获得一个ZipEntry对象后,需要调用closeEntry来关闭当前的ZipEntry对象。以便访问下一个ZipEntry对象。
如:
1 | var zin = new ZipInputStream(new FileInputStream(zipname)); |
写入ZIP文档
在写如ZIP文档时,大致步骤如下:
获得一个
ZipOutputStream。其构造器接受一个OutputStream对象。可以用FileOutputStream对象。新建
ZipEntry对象。构造器为ZIP项的名字,其他信息将自动设置,也可以自己手动调用setXXX方法覆盖。调用
ZipOutoutStream的putNextEntry方法来写出新文件,并将文件数据发送到ZIP输出流中。完成后调用
closeEntry。
如:
1 | var fout = new FileOutputStream("test.zip"); |
ZipFile
另外还有一个ZipFile,用于创建Zip文件。其有以下ZPI:
ZipFile(String name, Charset charset)ZipFile(File file, Charset charset):创建一个ZipFile,用于从给定的字符串或File对象读入文件。其中编码用于文件的名字和注释。Enumeration entries():返回一个Enumeration对象,他枚举描述了这个ZipFile中各个项中的ZipEntry对象。ZipEntry getEntry(String name):返回给定名字所对应的项。不存在的时候返回null。InputStream getInputStream(ZipEntry ze):返回用于给定项的InputStream。String getName():返回这个ZIP文件的路径。
对象输入/输出流与序列化
上面简单演示了如何将一个对象存储到文件系统,但是其具有很多缺点,例如多态的问题。而Java语言支持一种称为对象序列化(object serialization)的非常通用的机制,它可以将任何对象写出到输出流中,并在之后将其读回。
保存和加载序列化对象
保存序列化对象
步骤如下:
- 获得一个
ObjectOutputStream对象out和目标对象obj。 - 调用
out.write(obj)来写入对象。
例如:
1 | ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("employee.dat")); |
加载序列化对象
步骤如下:
- 获得一个
ObjectInputStream对象in。 - 调用
in.readObject()按照写入的顺序来获取对象。
例如:
1 | ObjectInputStream in = new ObjectInputStream(new FileInputStream("employee.dat")); |
Note:这里只能按照写入时的顺序来读取。
前提和原理
前提
要进行序列化的对象必须要实现了Serializable接口,该接口没有任何方法。
原理
之所以叫序列化,是因为每个序列化的对象都用一个序列号(serial number)来保存的。所以对于嵌套的对象,其算法如下:
- 对遇到的每个对象引用都关联一个序列号。
- 对于每个对象,当第一次遇到时,保存期对象数据到输出流中。
- 如果某个对象之前已经被保存过,那么只写出“与之前保存过的序列号为x的对象相同”。
而读回对象时,整个过程是反过来的。
- 对于对象输入流中的对象,第一次遇到其序列号时,构建它,并使用流中的数据来初始化它,然后记录这个序列号和新对象之间的关联。
- 当遇到“与之前保存过的序列号为x的对象相同”这一标记时,获取这个序列号相关联的对象引用。
修改默认的序列化机制
序列化有其默认的逻辑,但实际上有时候我们需要自定义某个域的存储逻辑。这个时候就可以修改其默认的序列化机制。
跳过数据域
使用transient修饰符可以跳过指定数据域的序列化。
如:
1 | public class User implements Serializable{ |
此时handle将不会被序列化,(一般进程序列化之后,下一次读取就并不具有时效性了)。
自定义内部序列化方法
通过重写目标对象的writeObject和readObject方法可以实现自定义序列化对象。
例如:
1 | package mw; |
值得注意的是:
- 字符串的长度仍然需要我们自定义(数据库的中
varchar需要定义长度可能也是这个原因吧),所以这里只展示了存储Integer,然后将其转化格式后存储到数据域中。 - 一旦对象中出现这两个方法,那么序列化时只会调用这两个方法,默认方法将不会起作用。
- 这两个方法是私有的
- 这两个方法仅仅为对象自己的数据与加载和保存对象,而不必去关系父类和其他任何信息。
自定义外部序列化方法
对于整体的对象的数据域(包括父类和其他)恢复和加载,则需要实现Externalizable接口。其定义了两个方法readExternal和writeExternal方法,目标对象必须重写这两个方法。即可以在内部为父类和其他的数据域进行赋值。
例如:
1 | public void readExternal(ObjectInput s) throws IOException{ |
注意:
- 这两个方法是
public的。因此也可以从外部访问。 readExternal还潜在地允许修改现有对象的状态。
序列化单例和类型安全的枚举
在序列化和反序列化时,如果目标对象是唯一的,那么必须小心,因为在序列化和反序列化后,对象的地址往往发生了变化,那么在Java虚拟机中,两者就不相等了。这种情况往往发生在自定义的枚举类型
例如:
1 | public class Orientation{ |
注意构造器是私有的,所以不能构造出HORIZONTAL和VERTICAL之外的对象。
那么此时,如果对HORIZONTAL,VERTICAL进行序列化和反序列化之后。得到新的NEW_HORIZONTAL,NEW_VERTICAL.
则极大概率HORIZONTAL != NEW_HORIZONTAL,VERTICAL != NEW_VERTICAL。
因为经过序列化和反序列化之后,得到的对象就是完全新的两个对象,与之前的对象都不同。
为克隆使用序列化
序列化往往可以用在深拷贝中,如JS中常用的
1 | let a = {}; |
而在Java中,也可以这样使用。原理也参见上一节的为什么不能对单例进行序列化,因为其本质就是另外的对象了,所以肯定就是深拷贝了。
操作文件
Path
Path在JDK7引入,其表示一个目录名序列,其后还可以跟着一个文件名。
Path对象使用Path.of()来创建。其有两个重载:
public static Path of(String first, String... more)public static Path of(URI uri)
一般使用第一个方法,而其第一个参数是根目录。后面接层级的目录名字。实际也可以直接赋值目录到第一个参数。而分开的好处是Java会自动选择对应系统的分隔符来组成目录。(如UNIX文件系统时/,而Windows时\)。
相对路径和绝对路径
可以通过Path对象提供的方法来获取一个相对目录。即在Path.of的第一个参数使用"path"而不是"\path"的方式。
Path.resolve(basePath, dir)
使用Path.resolve(basePath, dir)可以查找basePath中的dir目录,并返回该目录的Path对象。
path.relative(q)
path.relative(q)可以返回相对于q相对于path的相对路劲。如path = /home/harry,而q = /home/fred/input.txt。则会返回../fred/input的Path路径。
Path.resolveSibling(basePath, siblingDir)
Path.resolveSibling(basePath, siblingDir)可以获取与basePath同级的siblingDir目录的Path对象。
path.normaliza()
path.normaliza()将移除多余的.和..部件。如,/home/harry/../fred/./input.txt规范化后将返回home/fred/input.txt。
path.toAbsolutePath()
path.toAbsolutePath()方法将返回路径的绝对地址,该绝对地址从根部件开始。如/home/fred/input.txt或c:\User\fred\input.txt。
读写文件
JDK7引入的Files类可以使读写普通文件更加简单。前面简单介绍了读操作 ,下面详细介绍其写API。
读文件
见前文
写文件
写文件主要使用以下两个API:
public static Path write(...)public static Path writeString(...)
如,写一个字符串到文件:
1 | Files.writeString(path, content, charset); |
而追加内容时,可以添加第三个参数:
1 | Files.write(path, content.getBytes(charset), StandardOption.APPEND); |
如果内容过长的话,就该使用流的方式来处理:
1 | InputStream in = Files.newInputStream(path); |
创建文件和目录
创建目录
可以使用Files.createDirectory(path)来创建新目录。
如果需要创建一个嵌套目录,即自动创建中间目录,则需要使用Files.createDirectories(path)。如:要创建dir/dir1/dir2目录,但dir1并不存在,则第二个API会自动创建dir1,而第一个会报错。
创建文件
可以使用Files.createFile(path)来创建一个新文件。如果文件存在则报异常。检查文件存在和创建文件是原子操作,如果文件不存在,那么文件会被创建,并且其他程序在此过程中是无法执行文件创建操作的。
创建临时目录、文件
还可以使用以下API在执行位置或者系统执行位置来创建临时目和文件
public static Path createTempFile(Path dir, String prefix, String suffix, FileAttribute<?>... attrs)public static Path createTempFile(String prefix, String suffix, FileAttribute<?>... attrs)public static Path createTempDirectory(Path dir, String prefix, FileAttribute<?>... attrs)public static Path createTempDirectory(String prefix, FileAttribute<?>... attrs)
注意文件名是由系统命名的,而我们只提供前后缀。如:createTempFile(null, ".txt")将在系统指定的临时文件目录创建一个诸如12231434456235423321.txt的文件。
复制、移动和删除文件
复制文件
可以用Files.copy(fromPath, toPath)来复制文件。
移动文件
可以使用Files.move(fromPath, toPath)来移动文件。
如果目标路径已存在,那么复制或移动将会失败。如果想要覆盖已有的目标路径,可以使用REPLACE_EXISTING选项。
如果想要复制所有的文件属性,可以使用COPY_ATTRIBUTES选项。
如:
1 | Files.copy(fromPath, toPath, StandardCopyOption.REPLACE_EXISTING,StandardCopyOption.COPY_ATTRIBUTES); |
如果要将移动定义为为原子性的,要么移动成功,要么原来的文件不变。可以使用ATOM_MOVE.
1 | Files.move(fromPath, toPath, StandardCopyOption.ATOMIC_MOVE); |
还可以价格你一个流复制到Path中,这表示想要将改输入流存储到硬盘上。类似地,还可以将一个Path复制到输出流中。可以使用以下的调用:
Files.copy(inputStream, toPath)Files.copy(fromPath, outputStream)
删除文件
可以使用Files.delete(path)。
但是这个API在文件不存在的时候会抛出异常。而以下方法不会存在这个问题:
1 | boolean deleted = Files.deleteIfExist(path); |
该方法还可以用来删除空目录。
下面是一些选项
StandardOpenOption选项 描述 READ 用于读取而打开 WRITE 用于写入而打开 APPEND 写入时在文件末尾追加 TRUNCATE_EXISTING 写入时移除文件已有内容 CREATE 自动在文件不存在的情况下创建文件 CREATE_NEW 创建文件时如果文件存在则创建失败 DELETE_ON_CLOSE 当文件被关闭时尽“可能”的删除该文件 SPARSE 给文件系统一个提示,表示文件是稀疏的 SYNC 对数据和元数据的每次更新都必须同步的写入到存储设备中 DSYNC 对文件数据每次更新都必须同步的写入到存储设备中 StandardCopyOption选项 描述 REPLACE_EXISTING 如果目标已存在,则替换他 COPY_ATTRIBUTES 复制文件的所有属性 ATOMIC_MOVE 原子性的移动文件
获取文件信息
下面的静态方法都会返回一个boolean值,表示检查路径的某个属性的结果:
existsisHiddenisReadable,isWritable,isExecutableisRegularFile,isDirectory,is SymbolicLinksize方法会返回文件的字节数。getOwner方法将文件的拥有者返回。(UserPrincipal对象)
用法如下:
1 | Files.exists(path); |
而其他的基本属性将会被封装在一个BasicFileAttributes接口中。可以通过以下方式获取:
1 | BasicFileAttributes attributes = Files.readAttributes(path, BasicFileAttributes.class); |
获取目录中的项
静态的Files.list方法将会返回可以读取目录中各个项的Stream<Path>对象。注意该方法不会列出深层目录内容,即只列出次级目录的项。如果要看到深层的目录内容,需要使用Files.walk方法来遍历。如:
1 | try(Stream<Path> entries = Files.walk(pathRoot)){ |
此外,还可以调用Files.walk(pathRoot, depth)来限制想要访问的树的深度。(默认是全部遍历)
使用目录流
还有一个DirectrotyStream对象(与IntegerStream等相似),所以使用这个对象更加合理。而不是泛型的流。可以使用Files.newDirectoryStream来获取该对象。例如:
1 | try(DirectrotyStream<Path> entries = Files.newDirectoryStream(dir)){ |
还可以使用glob模式来过滤文件,如:
1 | DirectrotyStream<Path> entries = Files.newDirectoryStream(dir, "*.java") |
下面是所有的glob模式
| 模式 | 描述 | 示例 |
|---|---|---|
| * | 匹配路径组成部分中0个或多个字符(不含子目录) | *.java |
| ** | 匹配跨目录边界的0个或多个字符(含子目录) | **.java |
| ? | 匹配一个字符 | demo?.java |
| […] | 匹配一个字符集([0-9]、[A-F]、[!0-9]) | demo[0-9].java |
| {…} | 匹配由逗号隔开的多个可选项之一 | *.{java, class} |
| \ | 转译上述任意模式中的字符以及\字符 |
ZIP文件系统
Path类会在默认文件系统中查找路径,即在用户本地磁盘中的文件。而还有别的文件系统,例如ZIP文件系统。例如:
1 | FileSystem fs = FileSystem.newFileSystem(Path.of(zipname), nmull); //zipname为默认文件系统中的zip文件名 |
接下来需要获取ZIP文件系统中的Path则可以使用fs.getPath(sourceName)的方式,如下是一个复制操作。
1 | Files.copy(fs.getPath(sourceName), targetPath); |
而fs.getPath就与默认文件系统中的Path.of类似。
内存映射文件
大多数操作系统都可以利用虚拟内存实现将一个文件或者文件得到一部分“映射”到内存中。然后这个文件就可以被当成内存数组的一部分来访问,这比传统的文件操作要块很多。
其主要是FileChannel类。基本操作如下:
1 | FileChannel channel = FileChannel.open(path, options); |
然后通过调用FileChannel类的map方法熊这个通道中获得一个ByteBuffer。
我们可以指定映射文件区域与映射模式。支持的模式有3种:
FileChannel.MapMode.READ_ONLY:所产生的缓冲区是只读的,任何对该缓冲区写入的尝试都会导致ReadOnlyBufferException。FileChannel.MapMode.READ_WRITE:所产生的缓冲区可读可写,任何修改都会在某个时刻写入到问家中。(注意,这个修改并不是即时的)FileChannel.MapMode.PRIVATE:所产生的缓冲区可读可写,但是任何的修改都不会传播到文件中,其是私有的。
一旦拥有了缓冲区,就可以使用ByteBuffer类和Buffer超类的方法来读写数据了。
如:
1 | Path path = Path.of("E:\\a.txt"); |
缓冲区支持顺序和随机数据访问,可以通过get和put来操作数据。例如:
1 | while(buffer.hasRemaining()){ |
1 | for(int i = ol i < buffer.limit(); i++){ |
此外,buffer还提供了
get(Int|Long|Short|Char|Float|Double)
put(Int|Long|Short|Char|Float|Double)
来进行确定的操作。
在恰当的时机、通道关闭或者调用force方法的时候,会将这些修改回写到文件中。
文件加锁机制
当多个进程同时要修改一个文件的时候,则两个进程之间必须存在交互来确保文件不随意被修改。所以为文件提供了加锁的机制。有以下几个API可供使用:
FileChannel.lock():会阻塞调用,知道获得锁。FileChannel.tryLock():将立即返回,要么返回锁;要么在锁不可获得情况下返回null。FileChannel.lock(long start, long size, boolean shared):与1一致,不过是锁定文件的一部分。FileChannel.tryLock(long start, long size, boolean shared):与2一致,不过是锁定文件的一部分。
shared参数表示是否是一个共享锁。如果为false,则表示是一个独占锁。而如果是true,则是一个共享锁,允许多个进程从文件中读入,并阻止任何进程获得独占的锁。单并非所有的操作系统都支持共享锁,因此可能获得的是独占锁。此时可以调用FileLock类的isShared方法来确定是否支持共享锁。
这个文件将保持锁定状态,直到通道关闭或者在锁上调用release方法。
文件共享锁可以使用try...Resource语句。
如:
1 | try(FileLock lock = channel.lock()){ |
注意
- 在某些操作系统中,文件加锁仅仅是建议性的,如果一个应用未获得锁,它依旧可以被另外一个应用并发锁定的文件执行写操作。
- 在某些操作系统中,不能在锁定一个文件的同时将其映射到内存中。
- 文件锁是由整个Java虚拟机持有的。如果两个应用由同一个虚拟机启动,那么他们不可能每一个都获得一个在同一个文件上的锁。当调用
lock和tryLock方法,如果虚拟机已经在同一个文件上持有了另外一个重叠锁,那么这两个方法将会抛出OverlappingFileLockException。 - 在一些系统中,关闭一个通道会释放由Java虚拟机持有的底层文件上的所有的锁。因此,在同一个锁定文件上应避免使用多个通道。
- 在网络文件系统上锁定文件高度依赖于系统的,因此应该尽量避免。