
使用视图
视图
视图是虚拟的表。与包含数据的表不同,视图只包含使用时动态检索数据的查询。
例如:
1 | SELECT cust_name, cust_contact |
此查询用来检索订购了某个特定产品的客户。任何需要这个数据的 人都必须理解相关表的结构,并且知道如何创建查询和对表进行联结。 为了检索其他产品(或多个产品)的相同数据,必须修改最后的WHERE子
句。
现在,假如可以把整个查询包装成一个名为productcustomers的虚 拟表,则可以如下轻松地检索出相同的数据:
1 | SELECT cust_name, cust_contact FROM productcustomers WHERE prod_id = 'TNT2'; |
这就是视图的作用。productcustomers是一个视图,作为视图,它 不包含表中应该有的任何列或数据,它包含的是一个SQL查询(与上面用以正确联结表的相同的查询)。
为什么使用视图
下面是视图的一些常见应用。
- 重用SQL语句。
- 简化复杂的SQL操作。在编写查询后,可以方便的重用它而不必指导它的基本查询细节。
- 使用表的组成部分而不是整个表。
- 保护数据。可以给用户授予表的特定部分的访问权限而不是整个表的访问权限。
- 更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。
在视图创建之后,可以用与表基本相同的方式利用它们。可以对视 图执行SELECT操作,过滤和排序数据,将视图联结到其他视图或表,甚至能添加和更新数据。
重要的是知道视图仅仅是用来查看存储在别处的数据的一种设施。 视图本身不包含数据,因此它们返回的数据是从其他表中检索出来的。在添加或更改这些表中的数据时,视图将返回改变过的数据。
视图的规则和限制
- 与表一样,视图必须唯一命名(不能给视图取与别的视图或表相 同的名字)。
- 对于可以创建的视图数目没有限制。
- 为了创建视图,必须具有足够的访问权限。这些限制通常由数据 库管理人员授予。
- 视图可以嵌套,即可以利用从其他视图中检索数据的查询来构造 一个视图。
ORDER BY可以用在视图中,但如果从该视图检索数据SELECT中也 含有ORDER BY,那么该视图中的ORDER BY将被覆盖。- 视图不能索引,也不能有关联的触发器或默认值。
- 视图可以和表一起使用。例如,编写一条联结表和视图的SELECT 语句。
使用视图
创建视图
使用CREATE VIEW关键词来创建视图。
例如:
1 | CREATE VIEW productscustomer AS |
这条语句创建一个名为productcustomers的视图,它联结三个表,以返回已订购了任意产品的所有客户的列表。
使用视图
如果执行SELECT * FROM productcustomers,将列出订购了任意产品的客户。
如果检索订购了TNT2的客户,可如下进行:
1 | SELECT cust_name, cust_contact FROM productcustomers WHERE prod_id = 'TNT2'; |
cust_name |
cust_contact |
|---|---|
| Coyote Inc. | Y Lee |
| Yosemite Place | Y Sam |
这条语句通过WHERE子句从视图中检索特定数据。在MySQL处 理此查询时,它将指定的WHERE子句添加到视图查询中的已有WHERE子句中,以便正确过滤数据。
创建可重用的视图:创建不受特定数据限制的视图是一种好办法。例如,上面创建的视图返回生产所有产品的客户而 不仅仅是生产TNT2的客户。扩展视图的范围不仅使得它能被 重用,而且甚至更有用。这样做不需要创建和维护多个类似
视图。
使用视图重新格式化检索出的数据
例如之前提到的在单个组合计算列中返回供应商名和位置:
1 | SELECT Concat(RTrim(vend_name),' (',RTrim(vend_country),')') |
现在,假如经常需要这个格式的结果。不必在每次需要时执行联结, 创建一个视图,每次需要时使用它即可。为把此语句转换为视图,可按如下进行:
1 | CREATE VIEW vendorlocation AS |
这条语句使用与以前的SELECT语句相同的查询创建视图。为了 检索出以创建所有邮件标签的数据,可如下进行:
1 | SELECT * FROM vendorlocation; |
vend_title |
|---|
| ACME (USA) |
| Anvils R Us (USA) |
| Furball Inc. (USA) |
用视图过滤不想要的数据
视图对于应用普通的WHERE子句也很有用。例如,可以定义 customeremaillist视图,它过滤没有电子邮件地址的客户。为此目的,可使用下面的语句:
1 | CREATE VIEW customeremiallist AS |
显然,在发送电子邮件到邮件列表时,需要排除没有电子邮件 地址的用户。这里的WHERE子句过滤了cust_email列中具有NULL值的那些行,使他们不被检索出来。
现在,可以像使用其他表一样使用视图customeremaillist。
1 | SELECT * FROM customeremiallist; |
cust_id |
cust_name |
cust_email |
|---|---|---|
| 10001 | Coyote Inc. | ylee@coyote.com |
| 10003 | Wascals | rabbit@wascally.com |
| 10004 | Yosemite Plca | sam@yosemite.com |
使用视图与计算字段
视图对于简化计算字段的使用特别有用。下面是前面提到的一 条SELECT语句。它检索某个特定订单中的物品,计算每种物品的总价格:
1 | SELECT prod_id, |
prod_id |
quantity |
item_price |
expanded_price |
|---|---|---|---|
| ANV01 | 10 | 5.99 | 59.90 |
| ANV02 | 3 | 9.99 | 29.97 |
| TNT2 | 5 | 10.00 | 50.00 |
为将其转换为一个视图,如下进行:
1 | CREATE VIEW orderitemsexpanded AS |
为检索订单20005的详细内容(上面的输出),如下进行:
1 | SELECT * FROM orderitemsexpanded WHERE order_num = 20005; |
odre_num |
prod_id |
quantity |
item_price |
expanded_price |
|---|---|---|---|---|
| 20005 | ANV01 | 10 | 5.99 | 59.90 |
| 20005 | ANV02 | 3 | 9.99 | 29.97 |
| 20005 | TNT2 | 5 | 10.00 | 50.00 |
更新视图
通常,视图是可更新的(即,可以对它们使用INSERT、UPDATE和 DELETE)。更新一个视图将更新其基表(视图本身没有数据)。如果你对视图增加或删除行,实际上是对其基表增加或删除行。
但是,并非所有视图都是可更新的。基本上可以说,如果MySQL不 能正确地确定被更新的基数据,则不允许更新(包括插入和删除)。这实际上意味着,如果视图定义中有以下操作,则不能进行视图的更新:
- 分组(使用GROUP BY和HAVING);
- 联结;
- 子查询;
- 并;
- 聚集函数;
- DISTINCT;
- 导出(计算)列。
换句话说,本章许多例子中的视图都是不可更新的。这听上去好像 是一个严重的限制,但实际上不是,因为视图主要用于数据检索。
一般,应该将视图用于检索(SELECT语句) 而不用于更新(INSERT、UPDATE和DELETE)。
TIP:视图从MySQL5开始支持。
存储过程
存储过程简单来说,就是为以后的使用而保存的一条或多条MySQL语句的集合,并且可以在调用时传入参数。传统来说,MySQL的存储过程就是MySQL中的函数,其组成函数的语句就是MySQL语句。
使用存储过程
创建存储过程
简单定义
可以通过CREATE PROCEDURE来创建存储过程。其格式与函数定义类似。
例如1:计算平均价格:
1 | CREATE PROCEDURE productpricing() |
如上,与VBS类型,需要声明BEGIN和END。
带参数的定义
与函数类似,存储过程是可以带参数的。
如:
1 | CREATE PROCEDURE productpricing( |
此存储过程接受3个参数:pl存储产品最低价格,ph存储产品 最高价格,pa存储产品平均价格。
每个参数必须具有指定的类型,这里使用十进制值。存储过程的参数允许的数据类型与表中使用的数据类型相同。
关键字OUT指出相应的参数用来从存储过程传出 一个值(返回给调用者)。MySQL支持
IN(传递给存储过程)、OUT(从存 储过程传出,如这里所用)INOUT(对存储过程传入和传出)类型的参 数。
存储过程的代码位于BEGIN和END语句内,如前所见,它们是一系列 SELECT语句,用来检索值,然后保存到相应的变量(通过指定INTO关键字)。
这里的参数也是和函数不同的地方,存储过程的参数可以是传入(形参传递),也可以是传出(类似于指针实参,将数据放入内存指定位置,则函数外也可以读取到)。
建立智能存储过程
所谓的智能存储过程,就是结合业务,编写结构更明确的存储结构。
其中包含这些前提知识:
存储过程的变量声明:
1
2SET 变量名 = 表达式值 [,variable_name = expression ...];
SET @l_int = 1;注意:使用set声明变量,所有MySQL变量都必须以@开始。以@开头的是自定义的,否则其被视为系统变量。
IF语句:
1
2
3
4
5IF condition THEN
do something;
ELSE
do otherthing;
END IF;CASE语句:
1
2
3
4
5
6
7
8CASE var
WHEN condition1 THEN
do thing1;
WHEN condition2 THEN
do thing2;
ELSE
do surplus things;
END CASE循环语句1(while…do):
1
2
3WHILE condition DO
do things
END WHILE;循环语句2(repeat):
1
2
3
4REPEAT
do things;
UNTIL condition;
END REPEAT;循环语句3(loop):
1
2
3
4
5
6LOOP_LABLE:LOOP
do thinngs
IF v >=5 THEN
LEAVE LOOP_LABLE;
END IF;
END LOOP;注释语句:
1
-- 使用“--”来表示注释,注意--后的空格
标号可以用在begin repeat while 或者loop 语句前,语句标号只能在合法的语句前面使用。可以跳出循环,使运行指令达到复合语句的最后一步。
内置函数:
字符类:
CHARSET(str):返回字串字符集CONCAT (string2 [,... ]):连接字串INSTR (string ,substring ):返回substring首次在string中出现的位置,不存在返回0LCASE (string2 ):转换成小写LEFT (string2 ,length ):从string2中的左边起取length个字符LENGTH (string ):string长度LOAD_FILE (file_name ):从文件读取内容LOCATE (substring , string [,start_position ] ): 同INSTR,但可指定开始位置LPAD (string2 ,length ,pad ):重复用pad加在string开头,直到字串长度为lengthLTRIM (string2 ):去除前端空格REPEAT (string2 ,count ):重复count次REPLACE (str ,search_str ,replace_str ):在str中用replace_str替换search_strRPAD (string2 ,length ,pad):在str后用pad补充,直到长度为lengthRTRIM (string2 ):去除后端空格STRCMP (string1 ,string2 ):逐字符比较两字串大小,SUBSTRING (str , position [,length ]):从str的position开始,取length个字符,
数字类:
ABS (number2 ):绝对值BIN (decimal_number ):十进制转二进制CEILING (number2 ):向上取整CONV(number2,from_base,to_base):进制转换FLOOR (number2 ):向下取整FORMAT (number,decimal_places ):保留小数位数HEX (DecimalNumber ):转十六进制
注:HEX()中可传入字符串,则返回其ASC-11码,如HEX(‘DEF’)返回4142143
也可以传入十进制整数,返回其十六进制编码,如HEX(25)返回19LEAST (number , number2 [,..]):求最小值MOD (numerator ,denominator ):求余POWER (number ,power ):求指数RAND([seed]):随机数ROUND (number [,decimals ]):四舍五入,decimals为小数位数] 注:返回类型并非均为整数,如:
相当于一门新的语言,使用这门语言来编写一个存储过程(函数)来得到确定的值。
变量作用域
内部的变量在其作用域范围内享有更高的优先权,当执行到 end。变量时,内部变量消失,此时已经在其作用域外,变量不再可见了,应为在存储过程外再也不能找到这个申明的变量,但是你可以通过 out 参数或者将其值指派给会话变量来保存其值。
1 | CREATE PROCEDURE proc3() |
调用存储过程
与函数一样,存储过程也是通过CALL关键词来调用,参数通过括号内来传递。
如:
1 | SET @pricelow = 0; |
检查存储过程
为显示用来创建一个存储过程的CREATE语句,使用SHOW CREATE PROCEDURE语句:
1 | SHOW CREATE PROCEDURE ordertotal; |
为了获得包括何时、由谁创建等详细信息的存储过程列表,使用SHOW PROCEDURE STATUS。
注意:MySQL从5开始支持存储过程。
游标
游标即可以在检索出的数据中,选择对应的行的一个标记,可以游动游标来获得新的数据。
值得注意的是:MySQL的游标只能在存储过程中使用。
使用游标步骤
- 在能够使用游标前,必须声明(定义)它。这个过程实际上没有 检索数据,它只是定义要使用的SELECT语句。
- 一旦声明后,必须打开游标以供使用。这个过程用前面定义的 SELECT语句把数据实际检索出来。
- 对于填有数据的游标,根据需要取出(检索)各行。
- 在结束游标使用时,必须关闭游标。
在声明游标后,可根据需要频繁地打开和关闭游标。在游标打开后, 可根据需要频繁地执行取操作。
创建游标
游标用DECLARE语句创建。DECLARE命名游标,并定义 相应的SELECT语句,根据需要带WHERE和其他子句。例如,下面的语句定 义了名为ordernumbers的游标,使用了可以检索所有订单的SELECT语句。
1 | CREATE PROCEDURE processorders() |
这里仅仅是声明,并没有进行查询。在定义后才可以进行剩下的操作。
打开和关闭游标
打开游标
通过OPEN关键字来打开游标。并且在处理OPEN语句时执行查询,存储检索出的数据以供浏览和滚 动。
如:
1 | OPEN ordernums; |
关闭游标
通过CLOSE语句来关闭游标。CLOSE释放游标使用的所有内部内存和资源,因此在每个游标 不再需要时都应该关闭。
如:
1 | CLOSE ordernums; |
在一个游标关闭后,如果没有重新打开,则不能使用它。但是,使 233 用声明过的游标不需要再次声明,用OPEN语句打开它就可以了。
整合过后就是:
1 | CREATE PROCEDURE processorders() |
使用游标数据
在一个游标被打开后,可以使用FETCH语句分别访问它的每一行。
使下一条FETCH语句检索下一行(不 重复读取同一行)。
例1:从游标中检索单个行(第一行)
1 | CREATE PROCEDURE processorders() |
其中FETCH用来检索当前行的order_num列(将自动从第一行开 始)到一个名为o的局部声明的变量中。对检索出的数据不做任何处理。
例2:循环检索数据,从第一行到最后一行:
1 | CREATE PROCEDURE processorders() |
与前一个例子一样,这个例子使用FETCH检索当前order_num 到声明的名为o的变量中。但与前一个例子不一样的是,这个例子中的FETCH是在REPEAT内,因此它反复执行直到done为真(由UNTIL done END REPEAT;规定)。为使它起作用,用一个DEFAULT 0(假,不结束)定义变量done。
而DECLARE CONTINUE HANDLER FOR SQLSSTATE '02000' SET done = 1;指定了SQLSTATE '02000'出现时,SET done=1。
例3:整合上面的例子
1 | -- Declare local variables |
这个例子中,我们增加了另一个名为t的变量(存储每个订 单的合计)。此存储过程还在运行中创建了一个新表(如果它不存在的话),名为ordertotals。这个表将保存存储过程生成的结果。FETCH 像以前一样取每个order_num,然后用CALL执行另一个存储过程(我们在 前一章中创建)来计算每个订单的带税的合计(结果存储到t)。最后,
用INSERT保存每个订单的订单号和合计。
TIP:MySQL从5开始支持游标。
触发器
所谓触发器,就是在某个操作发生时由MySQL自发的执行其他另外的操作。
例如:
- 每当增加一个顾客到某个数据库表时,都检查其电话号码格式是 否正确,州的缩写是否为大写;
- 每当订购一个产品时,都从库存数量中减去订购的数量;
- 无论何时删除一行,都在某个存档表中保留一个副本。
所有这些例子的共同之处是它们都需要在某个表发生更改时自动 处理。这确切地说就是触发器。触发器是MySQL响应以下任意语句而 自动执行的一条MySQL语句(或位于BEGIN和END语句之间的一组语
句):
DELETEINSERTUPDATE
其他MySQL语句不支持触发器。
创建触发器
在创建触发器时,需要给出4条信息:
- 唯一的触发器名;
- 触发器关联的表;
- 触发器应该响应的活动(DELETE、INSERT或UPDATE);
- 触发器何时执行(处理之前或之后)。
保持每个数据库的触发器名唯一:在MySQL 5中,触发器名必 须在每个表中唯一,但不是在每个数据库中唯一。这表示同一 数据库中的两个表可具有相同名字的触发器。这在其他每个数 据库触发器名必须唯一的DBMS中是不允许的,而且以后的 MySQL版本很可能会使命名规则更为严格。因此,现在最好
是在数据库范围内使用唯一的触发器名。
可以使用CREATE TRIGGER语句创建。
例如:
1 | CREATE TRIGGER newproduct AFTER INSERT ON products FOR EACH ROW SELECT 'Product added'; |
CREATE TRIGGER用来创建名为newproduct的新触发器。
AFTER INSERT指定了触发器响应的活动。
ON products指示了在哪张表格触发。
FOR EACH ROW 指示了每一次插入都会触发。
SELECT 'Product added'指示了触发器触发的操作。
为了测试这个触发器,使用INSERT语句添加一行或多行到products 中,你将看到对每个成功的插入,显示Product added消息。
仅支持表:只有表才支持触发器,视图不支持(临时表也不 支持)。
注意:
- 触发器按每个表每个事件每次地定义,每个表每个事件可以允许多个触发器。比如,可以定义一张表上两个
BEFORE UPDATE触发器,默认会按照定义的顺序触发,想要改变顺序,可以通过指定FOLLOWS | PRECEDES [trigger name]来调整顺序。 - 单一触发器不能与多个事件或多个表关联,所 以,如果你需要一个对INSERT和UPDATE操作执行的触发器,则应该定义两个触发器。
- 如果BEFORE触发器失败,则MySQL将不执行请求的操作。此外,如果BEFORE触发器或语句本身失败,MySQL将不执行AFTER触发器(如果有的话)。
- 级联外键操作不会激活触发器。
删除触发器
删除触发器只需要用DROP TRIGGER即可。
例如:
1 | DROP TRIGGER newproduct; |
触发器不能更新或覆盖。为了修改一个触发器,必须先删除它, 然后再重新创建。
使用触发器
INSERT触发器
INSERT触发器在INSERT语句执行之前或之后执行。需要知道以下几 点:
- 在INSERT触发器代码内,可引用一个名为NEW的虚拟表,访问被 插入的行;
- 在BEFORE INSERT触发器中,NEW中的值也可以被更新(允许更改 被插入的值);
- 对于AUTO_INCREMENT列,NEW在INSERT执行之前包含0,在INSERT 执行之后包含新的自动生成值。
例如:
1 | CREATE TRIGGER neworder ALTER INSERT ON orders |
此代码创建一个名为neworder的触发器,它按照AFTER INSERT ON orders执行。在插入一个新订单到orders表时,MySQL生成一个新订单号并保存到order_num中。触发器从NEW. order_num取得 这个值并返回它。此触发器必须按照AFTER INSERT执行,因为在BEFORE INSERT语句执行之前,新order_num还没有生成。对于orders的每次插
入使用这个触发器将总是返回新的订单号。
测试:
1 | INSERT INTO orders(order_date, cust_id) VALUES (Now(), 10001); |
order_num |
|---|
| 20010 |
orders包含3个列。order_date 和 cust_id必须给出, order_num由MySQL自动生成,而现在order_num还自动被返回。
DELETE触发器
DELETE触发器在DELETE语句执行之前或之后执行。需要知道以下两 点:
- 在DELETE触发器代码内,你可以引用一个名为OLD的虚拟表,访问被删除的行;
- OLD中的值全都是只读的,不能更新。
例如:
1 | CREATE TRIGGER deleteorder BEFORE DELETE ON orders |
在任意订单被删除前将执行此触发器。它使用一条INSERT语句 将OLD中的值(要被删除的订单)保存到一个名为archive_orders的存档表中(为实际使用这个例子,你需要用与orders相同的列创建一个名为archive_orders的表)。
使用BEFORE DELETE触发器的优点(相对于AFTER DELETE触发器 来说)为,如果由于某种原因,订单不能存档,DELETE本身将被放弃。
多语句触发器:正如所见,触发器deleteorder使用BEGIN和 END语句标记触发器体。这在此例子中并不是必需的,不过也 没有害处。使用BEGIN END块的好处是触发器能容纳多条SQL语句(在BEGIN END块中一条挨着一条)。
UPDATE
UPDATE触发器在UPDATE语句执行之前或之后执行。需要知道以下几 点:
- 在UPDATE触发器代码中,你可以引用一个名为OLD的虚拟表访问 以前(UPDATE语句前)的值,引用一个名为NEW的虚拟表访问新更新的值;
- 在BEFORE UPDATE触发器中,NEW中的值可能也被更新(允许更改 将要用于UPDATE语句中的值);在BEFORE UPDATE触发器中,NEW中的值可能也被更新(允许更改 将要用于UPDATE语句中的值);
- OLD中的值全都是只读的,不能更新。
例如:
1 | CREATE TRIGGER updatevndor BEFORE UPDATE ON vendors |
何数据净化都需要在UPDATE语句之前进行,就像这个例子中一样。每次更新一个行时,NEW.vend_state中的值(将用来更新表行的值)都用Upper(NEW.vend_state)替换。
事务
事务处理(transaction processing)可以用来维护数据库的完整性,它 保证成批的MySQL操作要么完全执行,要么完全不执行。
下面是一些事务的关键词:
- 事务(transaction):指一组SQL语句;
- 回退(rollback):指撤销指定SQL语句的过程;
- 提交(commit):指将未存储的SQL语句结果写入数据库表;
- 保留点(savepoint):指事务处理中设置的临时占位符(placeholder),你可以对它发布回退(与回退整个事务处理不同)。
控制事务处理
管理事务处理的关键在于将SQL语句组分解为逻辑块,并明确规定数 据何时应该回退,何时不应该回退。
开始事务
可以通过以下语句来标识一个事务的开始:
1 | START TRANSACTION; |
使用回滚(ROLLBACK)
MySQL的ROLLBACK命令用来回退(撤销)MySQL语句。
例如:
1 | SELECT * FROM ordertaotal; |
这个例子从显示ordertotals表(此表在第24章中填充)的内 容开始。首先执行一条SELECT以显示该表不为空。然后开始一个事务处理,用一条DELETE语句删除ordertotals中的所有行。另一条 SELECT语句验证ordertotals确实为空。这时用一条ROLLBACK语句回退 START TRANSACTION之后的所有语句,最后一条SELECT语句显示该表不为空。
显然,ROLLBACK只能在一个事务处理内使用(在执行一条START TRANSACTION命令之后)。
事务处理用来管理INSERT、UPDATE和 DELETE语句。你不能回退SELECT语句。(这样做也没有什么意 义。)你不能回退CREATE或DROP操作。事务处理块中可以使用这两条语句,但如果你执行回退,它们不会被撤销。
提交事务(COMMIT)
一般的MySQL语句都是直接针对数据库表执行和编写的。这就是所谓的隐含提交(implicit commit),即提交(写或保存)操作是自动进行的。
对于多条语句,要想组成一个事务,可以手动开始事务和提交,例如:
1 | START TRANSACTION; |
在这个例子中,从系统中完全删除订单20010。因为涉及更新 两个数据库表orders和orderItems,所以使用事务处理块来
保证订单不被部分删除。最后的COMMIT语句仅在不出错时写出更改。如 果第一条DELETE起作用,但第二条失败,则DELETE不会提交(实际上,它是被自动撤销的)。
隐含事务关闭:当COMMIT或ROLLBACK语句执行后,事务会自 动关闭(将来的更改会隐含提交)。
使用保留点
简单的ROLLBACK和COMMIT语句就可以写入或撤销整个事务处理。但 是,只是对简单的事务处理才能这样做,更复杂的事务处理可能需要部分提交或回退。
在事务中,通过以下语句来标记保留点:
1 | SAVEPOINT pointName; |
而在使用回滚时,则不是简单的ROLLBACK,而是使用以下的语句:
1 | ROLLBACK TO pointName; |
保留点越多越好:可以在MySQL代码中设置任意多的保留 点,越多越好。保留点越多,你就越能按自己的意愿灵活地进行回退。
释放保留点:保留点在事务处理完成(执行一条ROLLBACK或 COMMIT)后自动释放。自MySQL 5以来,也可以用RELEASE SAVEPOINT明确地释放保留点。
更改默认的提交行为
正如所述,默认的MySQL行为是自动提交所有更改。换句话说,任何 时候你执行一条MySQL语句,该语句实际上都是针对表执行的,而且所做的更改立即生效。为指示MySQL不自动提交更改,需要使用以下语句:
1 | SET autocommit=0; |
autocommit标志决定是否自动提交更改,不管有没有COMMIT 语句。设置autocommit为0(假)指示MySQL不自动提交更改(直到autocommit被设置为真为止)。
全球化和本地化
数据库表被用来存储和检索数据。不同的语言和字符集需要以不同 的方式存储和检索。因此,MySQL需要适应不同的字符集(不同的字母和字符),适应不同的排序和检索数据的方法。
在讨论多种语言和字符集时,将会遇到以下重要术语:
- 字符集为字母和符号的集合;
- 编码为某个字符集成员的内部表示;
- 校对为规定字符如何比较的指令。
使用字符集和校对顺序
MySQL支持众多的字符集。为查看所支持的字符集完整列表,使用 以下语句:
1 | SHOW CHARACTER SET; |
这条语句显示所有可用的字符集以及每个字符集的描述和默认 校对。
为了查看所支持校对的完整列表,使用以下语句:
1 | SHOW COLLATION; |
此语句显示所有可用的校对,以及它们适用的字符集。
为了给表指定字符集和校对,可使用带子句的CREATE TABLE:
1 | CREATE TABLE mytable( |
此语句创建一个包含两列的表,并且指定一个字符集和一个校对顺序。
一般,MySQL使用以下规则来确定表格的字符集和校对顺序。
- 如果指定CHARACTER SET和COLLATE两者,则使用这些值。
- 如果只指定CHARACTER SET,则使用此字符集及其默认的校对(如 SHOW CHARACTER SET的结果中所示)。
- 如果既不指定CHARACTER SET,也不指定COLLATE,则使用数据库 默认。
除了能指定字符集和校对的表范围外,MySQL还允许对每个列设置 它们,如下所示:
1 | CREATE TABLE mytable |
这里对整个表以及一个特定的列指定了CHARACTER SET和 COLLATE。
如前所述,校对在对用ORDER BY子句检索出来的数据排序时起重要 的作用。如果你需要用与创建表时不同的校对顺序排序特定的SELECT语句,可以在SELECT语句自身中进行:
1 | SELECT FROM customers |
此SELECT使用COLLATE指定一个备用的校对顺序(在这个例子 中,为区分大小写的校对)。这显然将会影响到结果排序的次序。
安全管理
访问控制
MySQL服务器的安全基础是:用户应该对他们需要的数据具有适当 的访问权,既不能多也不能少。换句话说,用户不能对过多的数据具有过多的访问权。
MySQL创建一个名为root的用户账号,它对整个MySQL服务 器具有完全的控制。你可能已经在本书各章的学习中使用root进行过登 录,在对非现实的数据库试验MySQL时,这样做很好。不过在现实世界 的日常工作中,决不能使用root。应该创建一系列的账号,有的用于管理,有的供用户使用,有的供开发人员使用,等等。
管理用户
MySQL用户账号和信息存储在名为mysql的MySQL数据库中。一般不需要直接访问mysql数据库和表(你稍后会明白这一点),但有时需要 直接访问。需要直接访问它的时机之一是在需要获得所有用户账号列表时。为此,可使用以下代码:
1 | USE mysql; |
user |
|---|
| root |
创建账号
可以使用CREATE USER语句来创建账号,
例:
1 | CREATE USER ben IDENTIFIED BY 'p@ssw0rd'; |
CREATE USER创建一个新用户账号。在创建用户账号时不一定需 要口令,不过这个例子用IDENTIFIED BY 'p@$$wOrd'给出了一个口令。
重命名账户
可以通过RENAME USER a TO b来进行用户重命名。
如:
1 | RENAME USER ben TO bforta; |
删除账户
可以通过DROP USER xxx来删除账户。
如:
1 | DROP USER bforta; |
设置访问权限
在创建用户账号后,必须接着分配访问权限。新创建的用户账号没有访 问权限。它们能登录MySQL,但不能看到数据,不能执行任何数据库操作。
查看权限
为看到赋予用户账号的权限,使用SHOW GRANTS FOR,如:
1 | SHOW GRANTS FOR bforta; |
| Grants for bforta@% |
|---|
| CRANT USAGE ON *.* TO “bforta ‘@”%* |
输出结果显示用户bforta有一个权限USAGE ON *.*。USAGE表 示根本没有权限(我知道,这不很直观),所以,此结果表示在任意数据库和任意表上对任何东西没有权限。
授予权限
为设置权限,使用GRANT语句。GRANT要求你至少给出以下信息:
- 要授予的权限;
- 被授予访问权限的数据库或表;
- 用户名。
例如:
1 | GRANT SELECT ON crashcource.* TO bforta; |
此GRANT允许用户在crashcourse.*(crashcourse数据库的所 有表)上使用SELECT。通过只授予SELECT访问权限,用户bforta对crashcourse数据库中的所有数据具有只读访问权限。
SHOW GRANTS反映这个更改:
1 | SHOW GRANTS FOR bforta; |
| Grants for bforta@% |
|---|
| GRANT USAGE ON *.* TO “bforta‘@’%’ |
| GRANT SELECT ON ‘crashcourse’ .* TO ‘bforta‘@’%’ |
每个GRANT添加(或更新)用户的一个权限。MySQL读取所有 授权,并根据它们确定权限。
撤销权限
GRANT的反操作为REVOKE,用它来撤销特定的权限。
例如:
1 | REVOKE SELECT ON crashcourse。* FROM bforta; |
这条REVOKE语句取消刚赋予用户bforta的SELECT访问权限。被 撤销的访问权限必须存在,否则会出错。
GRANT和REVOKE可在几个层次上控制访问权限:
- 整个服务器,使用
GRANT ALL和REVOKE ALL; - 整个数据库,使用
ON database.*; - 特定的表,使用
ON database.table; - 特定的列;
- 特定的存储过程。
下面时所有的权限。

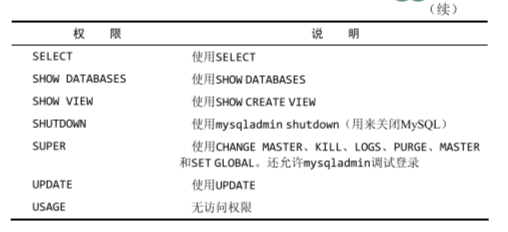
更改口令
为了更改用户口令,可使用SET PASSWORD语句。新口令必须如下加密:
1 | SET PASSWORD FOR bforta = Password('n3w p@$$w0rd'); |
SET PASSWORD还可以用来设置你自己的口令:
1 | SET PASSWORD = Password('n3w p@$$w0rd'); |
数据库维护
像所有数据一样,MySQL的数据也必须经常备份。由于MySQL数据 库是基于磁盘的文件,普通的备份系统和例程就能备份MySQL的数据。 但是,由于这些文件总是处于打开和使用状态,普通的文件副本备份不一定总是有效。
下面列出这个问题的可能解决方案。
- 使用命令行实用程序mysqldump转储所有数据库内容到某个外部 文件。在进行常规备份前这个实用程序应该正常运行,以便能正确地备份转储文件。
- 可用命令行实用程序mysqlhotcopy从一个数据库复制所有数据 (并非所有数据库引擎都支持这个实用程序)。
- 可以使用MySQL的
BACKUP TABLE或SELECT INTO OUTFILE转储所 有数据到某个外部文件。这两条语句都接受将要创建的系统文件 名,此系统文件必须不存在,否则会出错。数据可以用RESTORE TABLE来复原。
查看日志文件
MySQL维护管理员依赖的一系列日志文件。主要的日志文件有以下 几种。
- 错误日志。它包含启动和关闭问题以及任意关键错误的细节。此 日志通常名为hostname.err,位于data目录中。此日志名可用
--log-error命令行选项更改。 - 查询日志。它记录所有MySQL活动,在诊断问题时非常有用。此 日志文件可能会很快地变得非常大,因此不应该长期使用它。此 日志通常名为hostname.log,位于data目录中。此名字可以用
--log命令行选项更改。 - 二进制日志。它记录更新过数据(或者可能更新过数据)的所有 语句。此日志通常名为hostname-bin,位于data目录内。此名字可以用
--log-bin命令行选项更改。注意,这个日志文件是MySQL5中添加的,以前的MySQL版本中使用的是更新日志。 - 缓慢查询日志。顾名思义,此日志记录执行缓慢的任何查询。这 个日志在确定数据库何处需要优化很有用。此日志通常名为 hostname-slow.log ,位于 data 目录中。此名字可以用
--log-slow-queries命令行选项更改。
在使用日志时,可用FLUSH LOGS语句来刷新和重新开始所有日志文件。
改善性能
下面是一些简单的可能改善MySQL性能的方法:
- MySQL是用一系列的默认设置预先配置的,从这些设置开始通常 是很好的。但过一段时间后你可能需要调整内存分配、缓冲区大 小等。(为查看当前设置,可使用
SHOW VARIABLES;和SHOW STATUS;。) - MySQL一个多用户多线程的DBMS,换言之,它经常同时执行多 个任务。如果这些任务中的某一个执行缓慢,则所有请求都会执 行缓慢。如果你遇到显著的性能不良,可使用
SHOW PROCESS LIST显示所有活动进程(以及它们的线程ID和执行时间)。你还可以用KILL命令终结某个特定的进程(使用这个命令需要作为管理员登录)。 - 总是有不止一种方法编写同一条
SELECT语句。应该试验联结、并、子查询等,找出最佳的方法。 - 使用
EXPLAIN语句让MySQL解释它将如何执行一条SELECT语句。 - 一般来说,存储过程执行得比一条一条地执行其中的各条MySQL 语句快。
- 应该总是使用正确的数据类型。
- *决不要检索比需求还要多的数据。换言之,不要用SELECT (除 非你真正需要每个列)。
- 有的操作(包括
INSERT)支持一个可选的DELAYED关键字,如果 使用它,将把控制立即返回给调用程序,并且一旦有可能就实际执行该操作。 - 在导入数据时,应该关闭自动提交。你可能还想删除索引(包括
FULLTEXT索引),然后在导入完成后再重建它们。 - 必须索引数据库表以改善数据检索的性能。确定索引什么不是一 件微不足道的任务,需要分析使用的SELECT语句以找出重复的
WHERE和ORDER BY子句。如果一个简单的WHERE子句返回结果所花 的时间太长,则可以断定其中使用的列(或几个列)就是需要索引的对象。 - 使用
UNION来替代一条包含多个OR的SELECT语句可以显著改善性能。 LIKE很慢。一般来说,最好是使用FULLTEXT而不是LIKE。- 数据库是不断变化的实体。一组优化良好的表一会儿后可能就面 目全非了。由于表的使用和内容的更改,理想的优化和配置也会改变。
- 最重要的规则就是,每条规则在某些条件下都会被打破。